
Мета роботи. Набути навичок у навчанні нейромережі розпізнавати зображення, звуки та пози без написання коду машинного навчання. Набути знань, як використати отриману модель у власних проектах, на сайтах, у програмах тощо.
Машинне навчання (Mashine Learning)
Штучний інтелект (AI) і машинне навчання (ML) часто використовуються як синоніми, але обидва насправді є різними, хоча й пов’язаними поняттями.
Штучний інтелект – це комп’ютерне програмне забезпечення, яке імітує способи мислення людей для виконання складних завдань, таких як аналіз, прогнозування та навчання. Машинне навчання — це підмножина штучного інтелекту, яка використовує алгоритми, навчені на основі даних, для створення моделей, здатних виконувати такі складні завдання. Сьогодні більшість завдань штучного інтелекту виконується за допомогою машинного навчання, тому ці два терміни часто використовуються як синоніми
Сервіс Teachable Machine
Веб-додаток від Google для створення моделей машинного навчання для широкого кола користувачів. Вхідні дані для обробки нейронна мережа отримує через веб-камеру. Це можуть бути різні об'єкти, певний рух або звук. Ви навчаєте комп’ютер розпізнавати ваші зображення, звуки та пози без написання коду машинного навчання. Потім використовуйте свою модель у власних проектах, на сайтах, у програмах тощо. Наприклад, можна навчити Teachable Machine при піднятою вгору долоні говорити «Hi». При піднятому вгору великому пальці - «Cool», а при здивованому обличчю з відкритим ротом - «Wow».
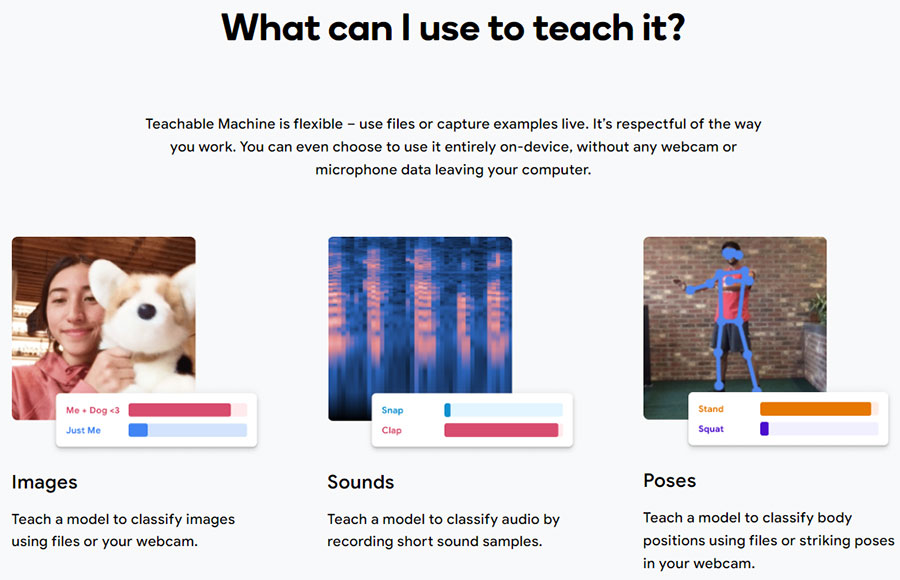
Рис.1. Типи данних для навчання
Використання мережі складається з 3 етапів
1. Збір даних для навчання системи. Дані збирає сам користувач, приклади групуються за класами чи категоріями, за якими буде відбуватися розпізнавання. Для початку потрібно навчити нейромережу. Для цього слід тримати кнопку «Hold to Record» і перед веб камерою показати об'єкт, вимовити слово або здійснити рух - сервіс робить кілька десятків знімків, для того, щоб знайти на зображеннях закономірність. Набір таких знімків прийнято називати «Data Set» (рис.2).
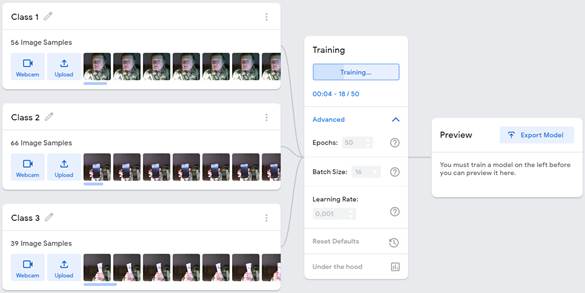
Рис. 2. Етап збору даних для навчння нейромережі
2. Навчання (тренування) нейромережі. Для того, щоб мережа могла розпізнавати візуальні, звукові або рухові образи її потрібно навчити. Для цього користувач має надати достатню кількість образів (об'єкт в різних проекціях, слово вимовлене в різному темпі чи тональності, дещо уповільнений чи пришвидшений рух), щоб мережа запам'ятала цей образ. Присутня кнопка для миттєвого тестування. У випадку неякісного розпізнавання, потрібно надати для навчання мережі більшу кількість образів. Teachable Machine демонструє ефективну «впевненість» - наскільки система «впевнена» у розпізнанні образа (рис.3).
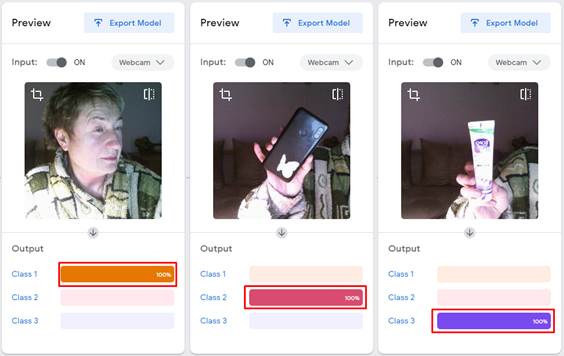
Рис.3. Результати навчання нейромережі, відсоток впевненості у розпізнаванні
Інструкція щодо навчання мережі.
3. Експорт навченої моделі. Навчену для певних образів мережу можна експортувати для різних проектів: сайтів, додатків тощо. Модель можна або завантажити на свій комп'ютер або розмістити її в Інтернеті (рис.4).
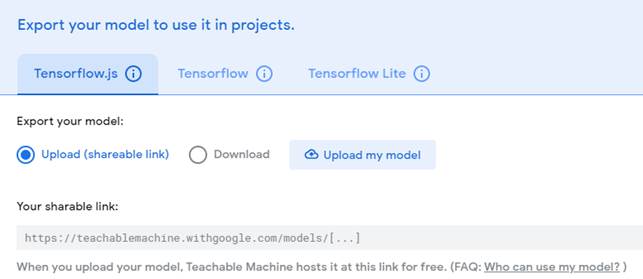
Рис. 4. Користувацький вибір для збереження моделі
Інструкція щодо експортування.
Використання сервісу є легким та наочним, опанування прийомами роботи є швидким, а отримані результати вражаючими. На сайті є докладна документація.
Моделі, створені за допомогою Teachable Machine, є моделями TensorFlow.js, тож ви можете експортувати їх і використовувати будь-де, де працює Javascript — наприклад, на веб-сайті, на сервері або в деяких програмах для створення прототипів, як-от Framer. Крім того, ви можете експортувати свою модель у деякі інші формати, щоб використовувати їх на інших платформах і середовищах. Дізнайтися більше про експорт і використання своєї моделі в Repo Github спільноти Teachable Machine.
- Teachable Machine Tutorial: Snap, Clap, Whistle
- Teachable Machine Tutorial: Bananameter
- Teachable Machine Tutorial: Head Tilt
Lobe ідентифікація та розпізнавання зображень
https://www.dz-techs.com/ru/create-machine-learning-model-microsoft-lobe
Lobe - безкоштовний настільний додаток для Windows і macOS, який дозволяє користувачам, які не мають досвіду програмування або аналізу даних, експериментувати зі штучним інтелектом і додавати можливості машинного навчання у власні програми. Користувач створює моделі машинного навчання, використовуючи простий візуальний інтерфейс замість написання коду.
Навчати систему дуже легко, достатньо вивантажити картинки, класифікувати, а потім виправляти помилки Lobe, доки він навчається. З кожним етапом ідентифікація вдосконалюватиметься. Більше даних – кращий результат.
Етапи створення моделі машинного навчання за допомоги функції классификації зображень Lobe.
Завантажити і встановити Microsoft Lobe.
Щоб отримати програму Lobe для Windows або macOS, натисніть кнопку «Завантажити» на сайті Lobe. Щоб приєднатися до бета-версії Lobe, потрібно ввести деякі особисті дані, включаючи ім'я, адресу електронної пошти та країну, але оскільки Microsoft не перевіряє цю інформацію, можна ввести будь-які дані.
Рис.5. Інтерфейс Microsoft Lobe
Програма працює в автономному режимі, і будь-які дані, які імпортуються, залишаються на комп'ютері користувача, а не завантажуються в хмару (і сервери Microsoft). Інсталяція є великим файлом (378 МБ на час написання), установка займає кілька хвилин. Після цього можна відразу почати використовувати Lobe, оскільки не потрібно налаштовувати жодні параметри.
Додати та потегувати фотографії.
Натиснути кнопку Новий проект у нижньому лівому куті головного екрана. Ввести назву проекту у верхньому лівому кутку екрана. Тепер можна додати кілька зображень і дати їм імена, щоб створити першу модель машинного навчання.
Натиснути кнопку "Імпортувати" у верхньому правому куті екрана та виберати спосіб додавання фотографій: з комп'ютера, за допомогою веб-камери або імпортувати наявний набір даних у вигляді впорядкованої папки для фотографій. Для першої моделі штучного інтелекту найкраще використати перший та найпростіший варіант.
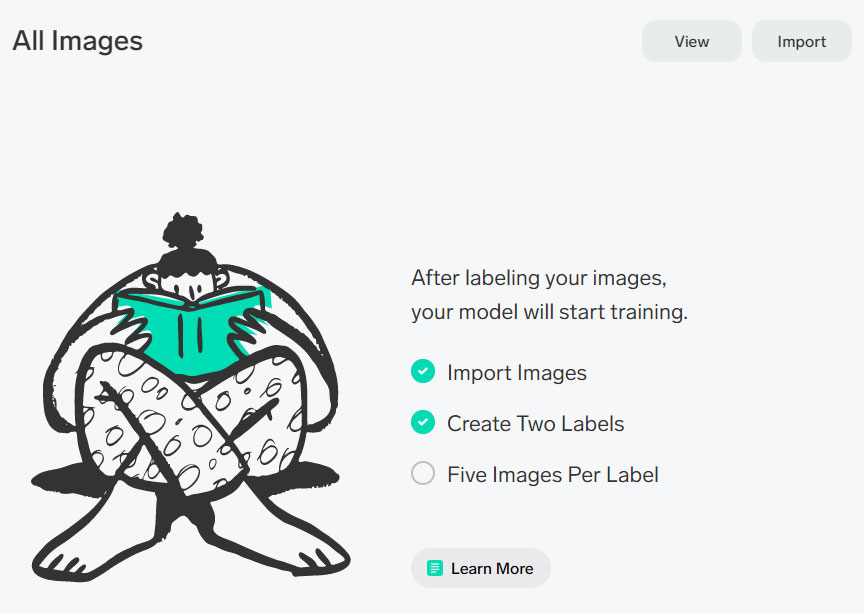
Рис.5. Вибір способу додавання фотографій
Вибрати щонайменше п'ять зображень одного об'єкта на твердому диску окремо або натиснувши та утримуючи Ctrl (або команда на Mac), клацнувши по ньому. В ідеалі фотографії об’єкта мають відрізнятися тлом, освітленням або розташуванням, щоб Lobe могла ідентифікувати важливі частини. Наприклад, вибрано зображення лисиці для цього прикладу.
Ввести описову позначку для першого зображення, яким у цьому прикладі є «Лисиця». Lobe збереже цю мітку, щоб можна швидко застосувати її до інших зображень у наборі даних. Клацнути правою кнопкою миші зображення, якщо потрібно відредагувати мітку або видалити зображення.
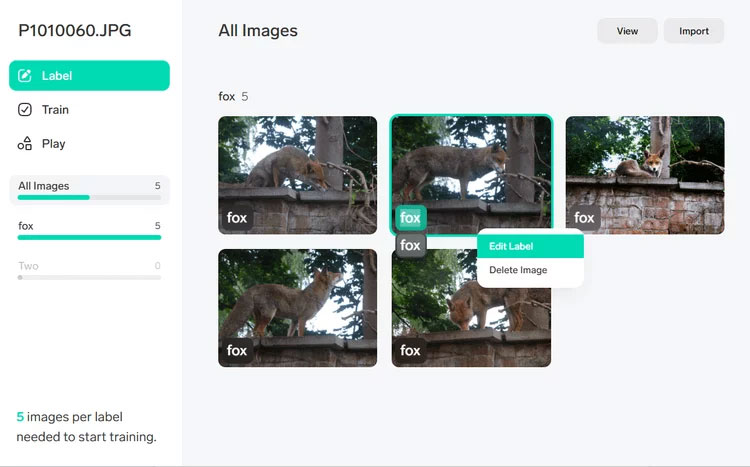
Рис.6. Позначення зображення мітками
Далі імпортувати наступний набір зображень іншого, але пов'язаного об'єкта. У цьому прикладі завантажено фотографії собак у Lobe, щоб відрізнити їх від зображень лисиці. Позначити перше зображення метатегом, потім застосувати цю мітку до інших знімків. За бажанням можна повторити процес для додаткових груп.
Навчання моделі машинного навчання.
Коли створено щонайменше дві мітки (їх треба застосувати як мінімум до п'яти зображень кожна), Lobe автоматично розпочне навчання моделі машинного навчання. Коли процес буде завершено, пролунає звук підтвердження.
Виберати параметр Train у лівому стовпчику, щоб відобразити результати. Навести вказівник на зображення, і буде повідомлення: "Прогноз правильний. Lobe правильно передбачає, що це зображення [назва ярлика]".
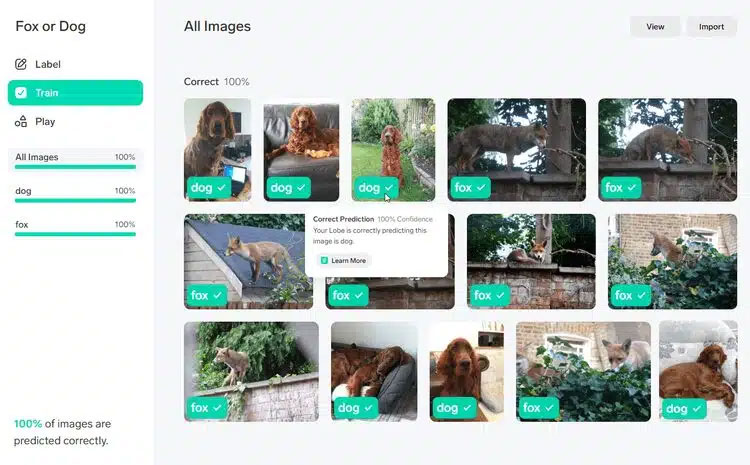
Рис.7. Отримання підтвердження правильного прогнозу
Можна перевірити, чи працює модель: імпортувати інше зображення, щоб побачити, чи передбачає Lobe правильну назву. Натиснути Play ліворуч, потім перетягнути зображення до програми або натиснути «Імпорт».
Якщо Lobe правильно передбачив назву імпортованого зображення, клацнути на зелену кнопку. Якщо ні, натиснути червону кнопку. Продовжувати додавати зображення, щоб навчити модель штучного інтелекту розпізнавати різні форми об'єкта. Microsoft пропонує використовувати від 100 до 1000 зображень на мітку, залежно від складності завдання.
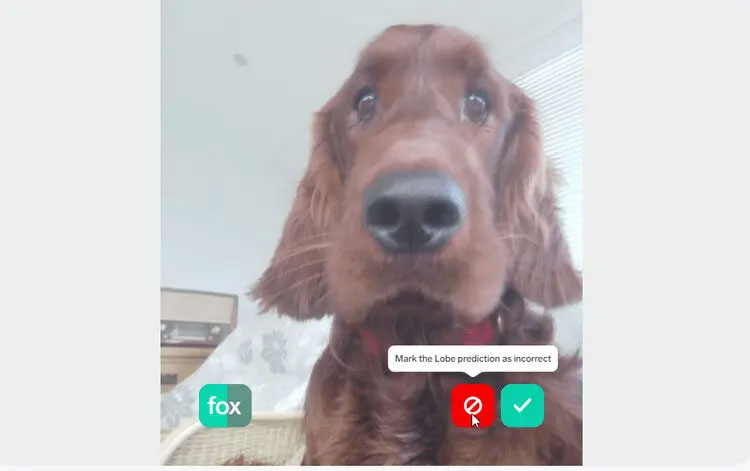
Рис.8. Зазначення вірного чи хибного прогнозу
Оптимізація моделі машинного навчання.
Якщо Lobe продовжує робити невірні прогнози, є кілька способів зробити модель машинного навчання надійнішою.
Перейти до розділу Train і натиснути кнопку View у верхньому правому кутку екрана і спочатку вибрати "Неправильно". Це покаже зображення, які часто плутають Lobe. Варто імпортувати більше варіантів цих неправильно маркованих зображень, щоб позначити їх як істинні чи хибні. Це зробить прогнози на майбутнє точнішими.
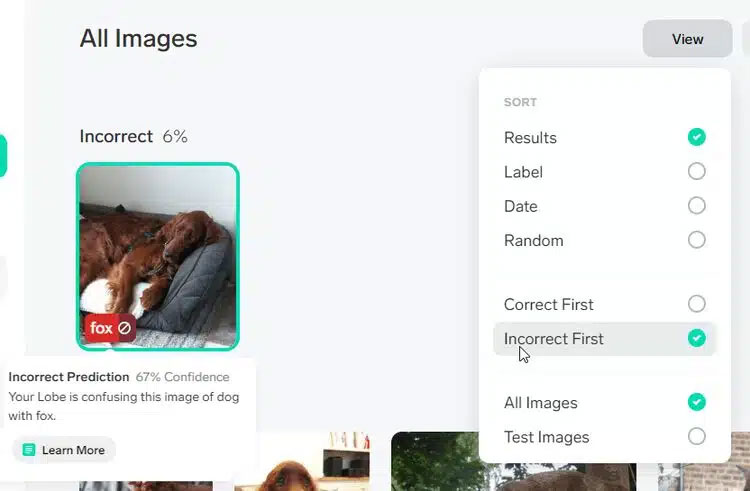
Рис.9. Ручне позначення вірних або не вірних міток
Lobe завжди передбачатиме одну із міток, навіть якщо імпортоване зображення не містить релевантного контенту. Щоб запобігти помилковій ідентифікації, додати зображення незв'язаних елементів та назвати їх «No», щоб у формі не доводилося вибирати між неправильними відповідями.
Якщо працювати з великим набором даних і стикнутися з множиною невірних прогнозів, можна змусити Lobe ретельніше навчити модель. Натиснути кнопку меню у верхньому лівому куті екрана та вибрати "Оптимізувати модель" та клацнути "Оптимізація".
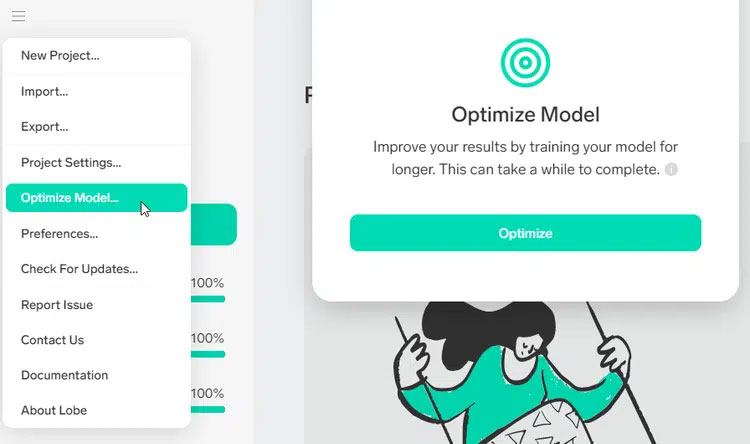
Рис.10. Оптимізація моделі
Експортувати шаблон моделі для використання у програмі.
Параметри Lobe можна налаштувати, він також дозволяє експортувати модель машинного навчання в стандартні формати, щоб використовувати її в інших програмах.
Можна експортувати набори даних у такому форматі, як TensorFlow Lite, для використання у додатках Android та у форматі Інтернету речей; Як Core ML для розробки програм iOS, iPad і macOS; і TensorFlow 1.15 SavedModel для використання у програмах, запрограмованих на Python.
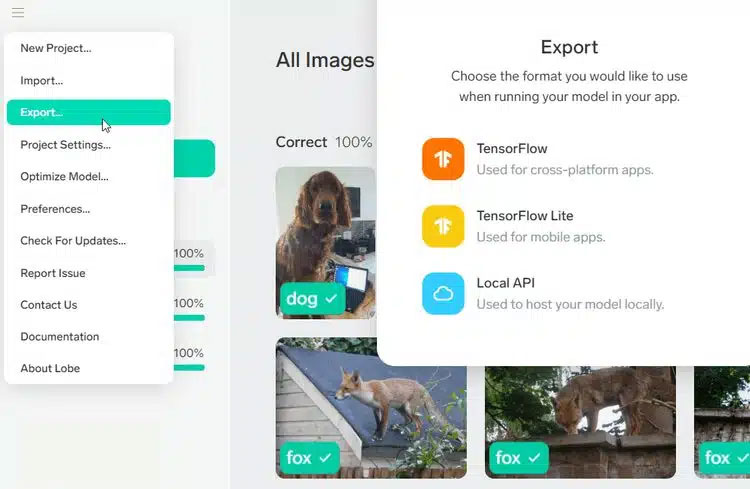
Рис.11. Експорт моделі
Натиснути кнопку меню у верхньому лівому куті екрана та вибрати Експорт за бажаним форматом. Перед збереженням моделі або файлів коду буде надано можливість покращити вашу модель. Lobe також має власний API для запуску експортованих форм у Python, .NET.
Якщо ці параметри здаються занадто складними для досвіду програмування, Lobe автоматично зберігає проект. Якщо потрібна технічна допомога та порада, можна відвідати групу LobeReddit.
Рис.12. Група LobeReddit
Microsoft Lobe пропонує простий візуальний спосіб створення базової моделі машинного навчання, не переймаючись кодом. Його можна використовувати для категоризації різних зображення або знімків екрана з веб-камери.
Навчання з підкріпленням ConvNetJS
Програма ConvNetJS відтворює алгоритм Deep Q Learning, описаний в Playing Atari with Deep Reinforcement Learning. Стаття презентує стандартний алгоритм Reinforcement Learning (Q Learning) для навчання грі в ігри Atari.
В даній демонстрації замість ігор Atari реалізовано 2D-агента, який має 9 очей, спрямованих під різними кутами вперед, і кожне око сприймає 3 значення вздовж свого напрямку (до певної максимальної відстані видимості): відстань до стіни, відстань до зеленої або червоної точки. Агент здійснює навігацію, використовуючи одну з 5 дій, які повертають його під різними кутами. Червоні точки — це яблука, і агент отримує позитивну винагороду за їх з’їдання. Зелені точки є отрутою, і агент отримує негативну винагороду за їх споживання. Тренування займає кілька десятків хвилин з поточними налаштуваннями параметрів.
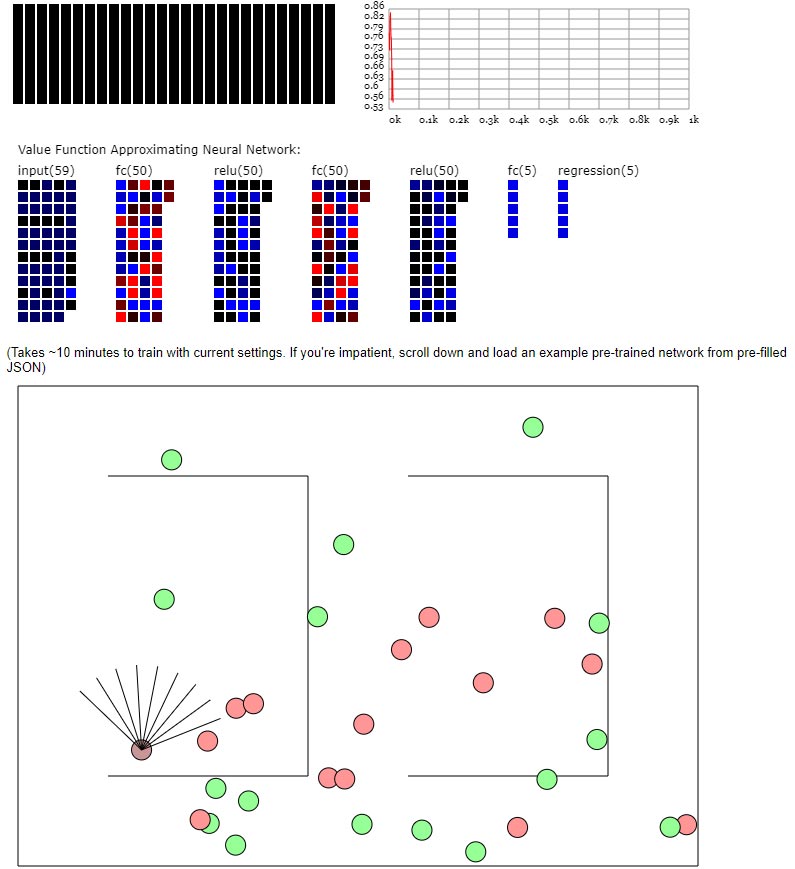
Рис.18. Навчання з підкріпленням 2D-агента
З часом агент вчиться уникати станів, які призводять до станів із низькими винагородами, і замість цього вибирає дії, які призводять до кращих станів.
Головною перевагою цього типу навчання є порівняна простота: спостерігаються дії агента і в залежності від результату його заохочують або штрафують, не пояснюючи, як саме потрібно діяти. Роль вчителя може грати зовнішнє середовище. В даному підході значної уваги приділяють заохоченню/штрафуванню не лише поточних дій, які безпосередньо призвели до позитивного/негативного результату, але і тих дій, які передували поточним.
Після визначення функції винагороди, потрібно визначити алгоритм, який буде використовуватися для знаходження стратегії, що забезпечує найкращий результат.
Відео лабораторної роботи
Контрольні запитання
- Назвіть основні завдання, де використання нейронної мережі буде ефективним.
- Що називають відстанню Хемінга, як вона вимірюється.
- Які основні етапи призначені для функціонування нейронної мережі.
- Які фактори є важливими для навчання нейронної мережі.
- Яка парадигма навчання є популярною для багатошарових перцептронів.
- З яких міркувань обирається кількість нейронів у вхідному, вихідному і прихованому прошарках в багатошарових перцептронах.
- Для чого проводиться нормалізація навчальних даних.
- В яких пропорціях обирають кількість навчальних та тестувальних даних
- Як довго проводиться навчання BackPropagation, за яких умов припиняється.
- Чим можна пояснити певні неточності у результатах навченої мережі.
Лабораторне завдання
- Ознайомитися з теоретичними матеріалами щодо машинного навчання нейронних мереж та їх застосування в задачах класифікації.
- На сервісі Teachable Machine здійснити кілька експериментів щодо розпізнавання образів: візуальних, звукових, рухомих, змішаних. Зазначити фактори, що впливають на якість розпузнавання. Зберегти модель.
- Встановити на комп’ютер програму Microsoft Lobe. Реалізувати власний проект з класифікації різних об’єктів.
- Ознайомитися з програмою ConvNetJS, що демонструє навчання з підкріпленням. Провести навчання (близько 10 хвилин) за різних параметрів. Зауважити, які параметри мають найбільший вплав на ефективність навчання.
- Під час захисту лабораторної роботи вільно володіти теоретичним матеріалом: особливості нейронних мереж, вимоги щодо даних, фактори, що впливають на результати навчання, усталені терміни, коло практичного застосування моделей.
Зміст звіту
- Назва та мета виконання лабораторної роботи.
- Скріни основних етапів експериментів, фрагменти навчальних множин, характеристики основних параметрів налаштування.
- Аналітичні висновки щодо властивостей нейронних мереж для розпізнавання та передбачення та отриманих результатів.