
Пошукові системи: склад, функції, принцип роботи
Пошукова система - це складний програмно-апаратний комплекс, що призначений для здійснення пошуку ресурсів в Інтернет, збереження відомостей про них в своїх базах і надання користувачу переліку посилань відповідно до його пошукового запиту.
Головним завданням пошукової системи є здатність надавати користувачам саме ту інформацію, яку вони шукають. А навчити користувачів робити «правильні» запити до пошукової системи, які відповідають її принципам роботи неможливо. Тому, розробники створюють такі алгоритми і принципи роботи пошукових систем, які найкраще пристосовані до поведінки і ходу думок пересічного користувача.
Пошукова система повинна діяти так само, як діє користувач при пошуку інформації і надавати за його запитом інформацію максимально швидко і просто. Користувач оцінює роботу системи за кількома основними критеріями. Чи знайшов він те, що шукав? Якщо не знайшов, то скільки разів йому довелося перефразувати запит, щоб знайти потрібне? Наскільки актуальною є надана інформація? Наскільки швидко пошукова машина обробляла запит? Наскільки зручно було представлено результати пошуку? Чи була потрібна інформація серед перших результатів пошуку? Як багато непотрібної інформації було знайдено нарівні з корисною?
Для того, щоб задовольнити зростаючим потребам користувачів, розробники пошукових машин постійно вдосконалюють алгоритми і принципи пошуку, додають нові функції і можливості, всіляко намагаються пришвидшити роботу системи.
Основні характеристики пошукової системи
Повнота - це відношення кількості знайдених за запитом документів до загальної кількості документів в Інтернет, що задовольняють даному запиту. Наприклад, якщо в Інтернеті є 100 сторінок, що містять словосполучення «Як вибрати автомобіль», а за відповідним запитом було знайдено всього 60 з них, то повнота пошуку буде 0,6. Очевидно, що чим повніше пошук, тим більше ймовірність, що користувач знайде потрібний документ.
Точність визначається ступенем відповідності знайдених документів до запиту користувача. Наприклад, якщо за запитом «Як вибрати автомобіль» знаходиться 100 документів, у 50 з них міститься словосполучення «Як вибрати автомобіль», а в інших просто наявні ці слова («як правильно вибрати магнітолу і встановити в автомобіль»), то точність пошуку вважається рівної 50/100 (= 0,5). Чим точніше пошук, тим швидше користувач знайде документи, що відповідають запиту і тим менше різного роду «сміття» серед них буде зустрічатися.
Актуальність характеризується часом з моменту публікації документів в Інтернет, до їх занесення до бази пошукової системи. Наприклад, на наступний день після появи цікавої новини, велика кількість користувачів звернеться до пошукових систем з відповідними запитами. Об'єктивно з моменту публікації новинної інформації на цю тему минуло менше доби, однак основні документи вже було проіндексовано і доступно для пошуку, завдяки існуванню у великих пошукових систем так званої «швидкої бази», яка оновлюється кілька разів на день.
Швидкість пошуку тісно пов'язана з стійкістю системи до навантажень. В робочі години до пошукових систем може надходити сотні запитів в секунду. Така завантаженість вимагає скорочення часу обробки окремого запиту. Тут інтереси користувачів та пошукової системи збігаються: відвідувач бажає отримати результати як можна швидше, а пошукова машина повинна обробити запит максимально оперативно, щоб не гальмувати обчислення наступних запитів.
Наочність представлення результатів є важливим компонентом зручного пошуку. До популярних запитів пошукова машина знаходить сотні, а то й тисячі документів. Внаслідок нечіткості складання запитів або неточності пошуку, навіть перші сторінки видачі не завжди містять лише потрібну інформацію. Це означає, що користувачеві часто доводиться здійснювати додатковий пошук всередині знайденого списку. Орієнтуватися в результатах пошуку допомагають різні елементи сторінки видачі пошукової системи.
Склад і принципи роботи пошукової системи
Практично всі великі пошукові системи мають свою власну структуру, відмінну від інших. Однак можна виділити загальні для всіх пошукових машин основні компоненти. Відмінності в структурі можуть бути лише у вигляді реалізації механізмів взаємодії цих компонентів.
Модуль індексування
Модуль індексування складається з трьох допоміжних програм (роботів):
Spider (павук) - програма, що призначена для завантажування веб-сторінок з навколишніх веб-серверів до заздалегідь заданого переліку адрес. Робот отримує від пошукової системи початковий список адрес документів (веб-сторінок), які він має відвідати, скопіювати вміст і віддати його на подальшу переробку до пошукової системи (вона перетворює ці документи в зворотні індекси).
Для завантаження сторінок роботи використовують протоколи HTTP. Робот передає на сервер запит "get / path / document" та інші команди HTTP-запиту. У відповідь робот отримує текстовий потік, що містить службову інформацію і безпосередньо сам документ. «Павук» витягує з документа html-код, посилання з відповідних тегів і редиректи (перескерування зі сторінки).
Кожна завантажена сторінка зберігається в базі в наступному форматі (прямий індекс):
- URL сторінки
- Дата, коли сторінка була завантажена на сервер
- HTTP-заголовок відповіді сервера
- Тіло сторінки (HTML-код)
Crawler («мандрівний» павук) - програма, яка автоматично проходить по всіх посиланнях, який зазначено на сторінці і здійснює індексацію нових документів, які до того не були занесені до баз пошукової системи.
Indexer (робот-індексатор) - програма, яка аналізує вміст веб-сторінки, що завантажили павуки. Індексатор розбирає сторінку на складові частини і аналізує їх, застосовуючи власні лексичні і морфологічні алгоритми. Аналізу піддаються різні елементи сторінки, такі як текст, заголовки, посилання, структурні та стильові особливості, спеціальні службові html-теги тощо.
Таким чином, модуль індексування дозволяє обходити по посиланнях задану множину ресурсів, завантажувати сторінки, витягувати з одержаних документів посилання на нові сторінки та здійснювати повний аналіз цих документів.
База даних
База даних, або індекс пошукової системи - це система зберігання даних, інформаційний масив, в якому зберігаються спеціальним чином перетворені параметри всіх завантажених і оброблених модулем індексування документів.
Пошуковий сервер
Пошуковий сервер є найважливішим елементом всієї системи, оскільки від його алгоритмів функціонування, безпосередньо залежить якість та швидкість пошуку.
Пошуковий сервер працює наступним чином:
- Отриманий від користувача запит піддається морфологічному аналізу. Генерується інформаційне оточення кожного документа, що міститься в базі (зворотній індекс).
- Отримані дані передаються в якості вхідних параметрів до спеціального модулю ранжирування. Відбувається обробка даних по всіх документах, в результаті чого, для кожного документа обчислюється власний рейтинг, що характеризує релевантність запиту, введеного користувачем, і різних складових цього документа, що зберігаються в індексі пошукової системи.
- Залежно від вибору користувача цей рейтинг може бути скориговано додатковими умовами (наприклад, так званий «розширений пошук»).
- Далі генерується сніппет, тобто, для кожного знайденого документа з таблиці документів витягуються заголовок, коротка анотація, найбільш відповідна до запиту і посилання на сам документ, причому знайдені слова виділено грубішим шрифтом.
- Отримані результати пошуку передаються користувачеві у вигляді SERP (Search Engine Result Page) - сторінки видачі пошукових результатів.
Як видно, всі ці компоненти тісно пов'язані один з одним і працюють у взаємодії, утворюючи чіткий, достатньо складний механізм роботи пошукової системи, що вимагає величезних витрат ресурсів.
Алгоритми роботи пошукових систем
Алгоритм прямого пошуку
Це метод простого перебору всіх сторінок (документів), що зберігаються в базі даних пошукової системи. Цей метод дозволяє напевно знайти потрібну інформацію не пропустивши нічого важливого, але він є не доречним для роботи з великими обсягами даних, бо пошук буде займати багато часу.
Алгоритм зворотного пошуку (інвертованих індексів)
Для ефективного пошуку у великих обсягах даних всі потужні пошукові системи використовують алгоритм зворотних (інвертованих) індексів.
За цим алгоритмом пошукові системи перетворюють документи в текстові файли, що містять перелік всіх наявних в документі слів. Слова в таких списках (індекс-файлах) розташовуються в алфавітному порядку і поряд з кожним словом зазначено координати його знаходження в документі та параметри, що визначають його статус в документі.
Це подібно до алфавітного покажчика слів в технічних або наукових книгах, де наводиться список використаних слів із зазначенням номерів сторінок, де вони зустрічаються.
Для формування сторінки видачі результатів пошуку пошукові системи шукають інформацію саме в зворотних індексах оброблених ними документів. Прямі індекси (оригінальний текст документів) пошуковики теж використовують, наприклад для складання фрагментів опису знайденого документу.
Для пошуку по зворотних індексах документів, що містяться в базі даних пошукових систем, використовується математична модель, що дозволяє спростити процес виявлення потрібних документів (за введеним користувачем пошукового запиту) і процес визначення релевантності всіх знайдених документів до цього запиту. Чим більше документ відповідає даному запиту, тим вище він розташований в пошуковій видачі.
Основним завданням математичної моделі будь-якої пошукової системи є пошук документів (сторінок) у своїй базі зворотних індексів відповідних до даного пошукового запиту і сортування цих знайдених документів у порядку зменшення їх релевантності до пошукового запиту. Використання простої логічної математичної моделі, яка знаходить документ, якщо в ньому зустрічається шукана фраза, не підходить, в силу величезної кількості таких документів.
Математична модель, яку використовується пошукові системи, відноситься до класу векторних математичних моделей. В ній використовується поняття ваги документа по відношенню до заданого користувачем запиту.
В базовій векторної математичної моделі вага документа за заданим пошуковим запитом обчислюється за двома основними параметрами: частотою, з якою зустрічається дане слово в аналізованому документі (TF - term frequency) і частотою, наскільки рідко це слово зустрічається у всіх інших документах колекції пошукової системи (IDF - inverse document frequency). Під колекцією пошукової системи розуміють всю сукупність документів, які відомі пошуковій системі. Перемноживши ці два параметри, отримується вага документа за заданим пошуковим запитом.
Природно, що різні пошукові системи, крім параметрів TF і IDF, використовують багато різних коефіцієнтів для обчислення ваги документа за заданим пошуковим запитом, але суть залишається незмінною: вага документа буде тим більше, чим частіше слово з пошукового запиту зустрічається в документі (до певних меж, після яких документ може бути визнано спамом) і чим рідше зустрічається це слово у всіх інших документах, проіндексованих пошуковою системою.
Оцінка якості роботи векторної математичної моделі пошукової системи
Формування видачи пошукових систем з тих чи інших запитів здійснюється автоматично за математичною моделлю без участі людини. Проте, жодна модель не може працювати ідеально, особливо на перших порах, тому, за роботою математичної моделі потрібно здійснювати контроль. Цей контроль здійснюють фахівці - ассесори, які переглядають видачу пошукових систем і оцінюють якість роботи математичної моделі пошукової системи.
Всі внесені ними зауваження враховуються розробниками, які відповідають за налаштування математичної моделі пошукової системи. У формулу векторної математичної моделі вносяться зміни або доповнення, в результаті чого якість роботи пошукової системи підвищується. Ассесори виконують роль своєрідного зворотного зв'язку між розробниками пошукової системи та її користувачами, який необхідний для поліпшення якості роботи пошуковиків.
Основними критеріями в оцінці якості роботи математичної моделі пошукових систем є:
- Точність видачі пошукової системи - відсоток релевантних документів, відповідних до пошукового запиту в пошуковій видачі.
- Повнота пошукової видачі - процентне відношення релевантних документів в пошуковій видачі до загальної кількості релевантних документів, наявних у всій колекції пошукової системи.
- Актуальність пошукової видачі - ступінь відповідності реального документа в Інтернеті, до того що про нього написано в пошуковій видачі. Наприклад, документ може вже не існувати або бути сильно зміненим, але при цьому в пошуковій видачі по заданому запиту він буде присутнім, незважаючи на його фізичну відсутність за вказаною адресою або ж на його поточну невідповідність до даного пошукового запиту. Актуальність видачі пошукової системи залежить від частоти сканування роботами документів і поновлення інформації в базах.
Сніппет документа
Сніппет в пошуковій видачі розташовується відразу під посиланням на знайдений документ (текст якої береться з тега TITLE документа):
Фрагмент сторінки видачі Яндекс
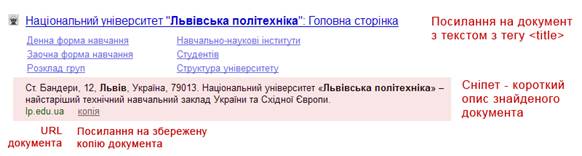
Фрагмент сторінки видачі Гугль
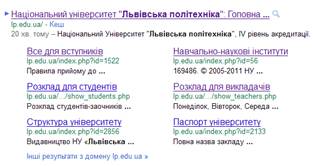
Для сніпету використовуються фрагменти тексту з прямого індексу. Ідеальний сніппет має надати користувачеві коротку змістовну інформацію про вміст документа. Сніппет формується автоматично, пошукова система сама формує фрагменти тексту документа. Для різних пошукових запитів один документ буде мати різні сніппети.
Сніппет не можна отримати з зворотного індексу, оскільки там зберігається інформація лише про використані на сторінці словах та їх розташуванні в тексті. Саме для створення фрагментів одного і того ж документа в різних пошукових видачах (за різними пошуковими запитами) пошуковики, окрім зворотного індексу, зберігають ще і прямий індекс, тобто копію документа, з якої зручно нарізати потрібні сніппети.
Формування сторінки пошукової видачі
В пошуковій видачі за заданим запитом зазвичай міститься лише один (релевантний до запиту) документ з кожного сайту. Пошукові системи зацікавлені в тому, щоб користувач отримував різноманітну інформацію з різних сайтів, а не гортати кілька сторінок пошукової видачі з документами одного сайту. Іноді, як виняток, допускається відображення в пошуковій видачі іншого документа з сайту, якщо цей документ виявиться також доречним.

Частото індексування сайтів
Логіка роботи пошукових систем з індексації документів (сторінок):
- Після знаходження і індексації нової сторінки, робот відвідує її наступного дня.
- Після порівняння вмісту сторінки з тим, що було вчора і не знайшовши відмінностей робот пошукової системи зайде на неї за три дні.
- Якщо і цього разу на даній сторінці нічого не змінитися, то робот навідується за тиждень і т.д.
З часом, частота відвідування пошукового робота до сторінки наблизиться до частоти її оновлення. Час повторного заходу робота пошукових систем може вимірюватися для різних сайтів як в хвилинах, так і в роках. Розумні пошукові системи встановлюють індивідуальний графік відвідування для різних сторінок різних сайтів.
Cемантичний вебпошук
http://internetno.net/category/obzoryi/crib/semantic-search/
Про семантичний пошук активно говорять впродовж кількох останніх років. Будь-яка технологія, яка зможе поліпшити вже стандартний пошук від Google, справедливо викликає загальний інтерес. Особливо якщо мова йде про можливості семантичного пошуку - адже кількість інформації в Мережі стрімко наростає, а можливості класичних пошукових механізмів досягли своєї технічної межі.
Провідні семантичні пошукові системи
Hakia (http://www.hakia.com/)
Hakia - це семантичний пошук загального призначення, який вважається одним з технологічних лідерів даного пошукового ринку. Hakia - це універсальний семантичний пошуковик, який є яскравою противагою відомих семантичних пошуковиків, як Powerset і Cognition, які добре шукають лише в тексті, що має чітку структуру (наприклад, Wikipedia).
Пошукові результати Hakia надаються в трьох закладках: веб-ресурси, що заслуговують довіри (як правило офіційні, державні, освітні і великі новинні сайти), зображення і новини. В закладці Довірені сайти відображено сайти або джерела, які було внесено в пошук, перевірено і схвалено командою модераторів пошуковика.
Для популярних запитів Hakia надає також тематичне резюме за даним запитом, де містяться перевірені інформативні та високоякісні посилання на статті та ресурси за заданою темою, а також коротка суть питання. Відвідувачі використовують тематичні резюме як стартову карту для занурення в тематичне питання.
Sensebot (http://www.sensebot.net/)
Гаслом пошуковика є "Sensebot шукає разом з вами". Кожна пошукова видача ретельно аналізується і відбувається угруповання схожих або ідентичних пунктів пошуку, а також чіткий підсумок змісту кожної з виділених тематичних груп (концепція «змістовного фолдінга»). Sensebot спроможний пробиратися через масиви даних будь-якого обсягу, легко знаходячи в них потрібні відомості.
Короткий зміст може налаштовуватися і представлятися в різних видах. За замовченням, це дайджест з вмістом сформованої змістовної групи, де наводяться важливі і релевантні факти з знайденого матеріалу. Дайджест-блок може містити хмару тегів з теми, а також список речень, які висловлюють головні ідеї цього змістовного блоку. Речення, як і теги, є посиланнями на конкретні сторінки або список сторінок ієрархічно пов'язаних з даним поняттям.
Cognition (http://www.cognition.com/)
Семантичний пошуковий механізм базується на лінгвістичної мапі англійської мови. Механізм створювався протягом останніх 24 років і на даний момент компанія-розробник стверджує, що ними складена найбільш точна в світі карта англійської мови та її змістовного простору. Можливості Cognition не обмежуються лише наданням публічного семантичного пошуку, його ресурси використовуються багатьма компаніями для створення своїх спеціалізованих пошуків, різної бізнес-аналітики, вбудованих сервісів машинних перекладів, пошуку по контексту тощо.
Напрями, де лідирує семантичний пошук Cognition:
- Пошук за законодавством, як міжнародним, так і суто американським, юридичні консультації. Як приклад, у Cognition накопичено базу окружних рішень американських судів, починаючи з 1950 р;
- Система MEDLINE (Medical Literature Analysis and Retrieval System Online) - один з кращих пошукових індексів у світі з медичної та наукової літератури, різних наукових даних. Лише у власній базі на цю тему зберігається понад 20 мільйонів оригінальних документів;
- Найкращий пошук по англійській версії Wikipedia - єдина змістовна карта понять і логічних значень, яку накладено поверх звичної Wikipedia, що надає додаткової вимір в просторі енциклопедії;
- Власна повнотекстова база Нового Завіту, з примітками перекладачів, паралельними текстами історичних оригіналів, історичними контекстними коментарями, вичерпною картою перехресних посилань всередині текстів, єдиної семантичної картою всього матеріалу.
DeepDyve (http://www.deepdyve.com/)
DeepDyve - це професійний дослідницький інструмент, що надається безкоштовно для публічного використання в некомерційних цілях. Пошуковик спеціалізується на індексуванні "глибокого Вебу", тобто тої частини веб-ресурсів, яка недоступна для звичайних пошукових машин.
Наприклад, Google не індексує текстове написання посилання типу "some.ru / somedir", DeepDyve виділяє подібні посилання з тексту і намагається врахувати цей ресурс.
Для DeepDyve достатньо зустріти одне посилання на будь-яку гілку нового для нього форуму, щоб він самостійно спробував визначити тип форумного движка і згенерувати посилання на інші гілки цього форуму, а також його головні індексні сторінки. Спеціальна команда добровольців щоденно реєструється на сотні нових популярних форумів, надаючи можливість DeepDyve заходити на них уповноваженим і бачити будь прихований для публічного спостерігача текст. DeepDyve також вільно індексує вміст SQL-баз даних і звичайних веб-сторінок, якщо йому стають відомими параметри доступу до них.
WolframAlpha (http://www.wolframalpha.com/)
В пошуковій системі WolframAlpha пошук сам генерує відповіді на запити користувачів. Тут, користувач не просто працює з індексного базою пошуковика, а спілкується з системою. WolframAlpha відноситься до останнього покоління семантичних пошуковиків, де вплив елементів штучного інтелекту є найбільш істотним. Багато реалізованих передових концепцій є науковими експериментами, яки проходять перевірку на реальних користувачах системи. Для реалізації цієї системи довелося розроблено нову науку - A New Kind of Science (NKS), яка є надбудовою над звичними принципами математики.
Семантичний пошук - це технологія майбутнього, яка ставить перед собою дуже амбітні цілі. І хоча семантичний пошук поки що не може повністю замінити Google в наданні якісніших результатів, семантичний пошук дозволяє ефективно вирішувати багато нестандартних та спеціалізованих завдання, отримувати відповіді на складні, логічно витончені запити .
Порядок роботи
- Ознайомитися з теоретичними засадами веб-пошуку.
- Уважно ознайомитися з інтерфейсами пошукових систем.
- Здійснити тестовий пошук в різних системах і проаналізувати отримані результати.
- Зробити висновки стосовно втілення інтелектуальних технологій в сучасний пошук.
Зміст звіту
- Назва та мета виконання лабораторної роботи.
- Проблематика семантичного пошуку
- Можливості систем стосовно змістовного пошуку в текстах, документах, картинках.
- Аналітичні висновки щодо властивостей сучасних пошуковиків та отриманих результатів.