|
Сучасний інтернет представляє унікальне безмежне сховище знань, де можна отримати відповідь практично на будь-яке питання. Фактично, тут зібрано все краще, що винайдено і створено людством як за всю його довгу історію, а також новинки, що з'явилися щойно.
Проте поява такої величезної і обширної бібліотеки не може не привести до перевантаженості інформаційного простору. Фахівці по-різному оцінюють розміри Інтернету, проте в більшості сходяться на думці, що зараз тут знаходяться мільярди сторінок, причому велика частина їх зникає або оновлюється протягом нетривалого періоду часу. Чи існує яка-небудь можливість орієнтуватися в цьому практично нескінченному невичерпному швидкозмінному потоці інформації?
Частково цю проблему вирішують спеціальні інформаційно-пошукові системи, які вміють самостійно збирати інформацію. Якщо розумно використати пошукову систему, можна на протязі достатньо короткого часу знайти інформацію, на пошук якої без використання Інтернет можна витратити місяці і навіть роки. Але, практика доводить, що зараз ефективно і правильно використовувати пошукові системи вміють не більше 3% чоловік і в результаті на запит з 1-2 слів отримують абсолютно даремну для себе інформацію.
СКЛАДОВІ ПОШУКОВИХ СИСТЕМ
Пошукові cистеми зазвичай мають три компоненти:
- агент (павук, кроулер або робот), який переміщується по мережі і збирає інформацію;
- база даних, яка містить інформацію, що зібрано павуками;
- пошуковий механізм, який користувачі використовують як інтерфейс для взаємодії з базою даних.
Засоби пошуку типу агентів, павуків, кроулерів і роботів використовуються для збору інформації про документи, які знаходяться в мережі Інтернет. Це спеціальні програми, які займаються пошуком сторінок в мережі, збирають гіпертекстові посилання з цих сторінок і автоматично індексують інформацію, яку вони знаходять для побудови бази даних. Кожний пошуковий механізм має власний набір правил, якими визначається збір документів.
- Агенти є найінтелектуальнішими з пошукових засобів. Вони можуть робити більше, ніж просто шукати: вони можуть виконувати транзакції від імені користувача. Вже зараз вони можуть шукати сайти специфічної тематики і повертати списки сайтів, відсортованих за їх відвідуваністю. Агенти можуть обробляти вміст документів, знаходити та індексувати інші види ресурсів, не лише сторінки. Вони можуть бути запрограмовані для витягання інформації з вже існуючих баз даних. Незалежно від інформації, яку агенти індексують, вони передають її назад до бази даних пошукового механізму.
- Павуки здійснюють загальний пошук інформації в Інтернет. Павуки повідомляють про зміст знайденого документа, індексують його і добувають підсумкову інформацію. Вони також переглядають заголовки, деякі посилання і відправляють проіндексовану інформацію до бази даних пошукового механізму.
- Кроулери переглядають заголовки і повертають тільки перше посилання.
- Роботи можуть бути запрограмовані таким чином, щоб переходити по різним посиланням різної глибини вкладеності, виконувати індексацію і перевіряти посилання в документі. Але, вони можуть застрягати в циклах, адже, проходячи за посиланнями, їм потрібні значні ресурси мережі. Існують методи, що забороняють роботам пошук по сайтах, власники яких не бажають, щоби вони були проіндексовані.
Агенти збирають та індексують різні види інформації. Деякі, наприклад, індексують кожне окреме слово у документі, в той час як інші індексують тільки 100 найбільш важливих слів в кожному документі, індексують розмір документу і кількість слів в ньому, назву, заголовки і підзаголовки і так далі. Вигляд побудованого індексу визначає, який пошук може бути проведений пошуковим механізмом і як отримана інформація буде інтерпретована.
Агенти знаходять інформацію, після чого її розміщують в базі даних пошукового механізму. Адміністратори пошукових систем визначають, які сайти або типи сайтів агенти мають відвідати та проіндексувати. Проіндексована інформація відправляється до бази даних пошукового механізму.
Користувачі можуть розміщувати інформацію прямо в індексі, заповнюючи особливу форму для того розділу, в який вони хотіли б помістити свою інформацію. Ці дані передаються базі даних.
Коли користувач хоче знайти інформацію, доступну в Інтернет, він відвідує сторінку пошукової системи і заповнює форму, що деталізує потрібну йому інформацію. Тут можуть використовуватись ключові слова, дати та інші критерії. Критерії в формі пошуку повинні відповідати критеріям, які використовуються агентами при індексації інформації, яку вони знайшли при переміщені по мережі.
База даних відшукує предмет запиту, що базується на інформації, яка вказана в заповненій формі, і виводить відповідні документи, що підготовані базою даних. Для того, щоб визначити порядок, в якому перелік документів буде показано, база даних застосовує алгоритм ранжування. В ідеальному випадку, розташованими першими в списку будуть документи, що є найбільш релевантними до запиту користувача.
Релевантність – основне поняття при індексації документа в пошукових системах. Релевантність – міра відповідності, тобто це відповідність змісту знайденої сторінки до запиту користувача. Але комп'ютер - не людина, і тому пошукові системи використовують спеціальні алгоритми для визначення релевантности. Теоретичних методів визначення релевантності більш ніж 20. Але виділяють два основні напрями: лінгвістичне (Рамблер, Яндекс) і статистичне (Google).
Основні російські пошукові системи (зокрема Рамблер) використовують лінгвістичний напрям, тобто пошуковий робот, переглядаючи сторінку, звертає увагу на "літературність" її написання ("чом ти не прийшов" буде більш релевантною, ніж "чом ти не травень прийшов").
Різні пошукові системи використовують різні алгоритми ранжування, однак основними принципами визначення релевантності є наступні:
- Кількість слів запиту у текстовому вмісті документу (тобто в html-коді).
- Теги, в яких ці слова розташовуються.
- Місцеположення шуканих слів у документі.
- Питома вага слів, відносно яких визначається релевантність, у загальній кількості слів документу.
Ці принципи застосовуються всіма пошуковими системами. А наведені нижче використовуються деякими, але достатньо відомими (наприклад, AltaVista).
- Час - як довго сторінка знаходиться в базі пошукового сервера. Спочатку здається, що це недолугий принцип. Але в Інтернет існує багато сайтів, час життя яких складає близько місяця. Якщо ж сайт існує досить довго, це значить, що його власник є досвідченим за даною темою і користувачу більше підійде сайт, що існує вже кілька років, ніж той, який з'явився тиждень тому за цією ж темою.
- Індекс цитованості - як багато посилань на дану сторінку веде з інших сторінок, що зареєстровані у базі пошуковика.
База даних виводить ранжований таким чином перелік документів з HTML і повертає його користувачу, який зробив запит. Різні пошукові механізми вибирають різні способи показу отриманого переліку - деякі відображають лише посилання, інші виводять посилання з декількома першими реченнями документу або заголовок документу разом з посиланням. Коли користувач звертається до посилання на один з документів, цей документ завантажується з сервера, на якому він знаходиться.
Велика частина цільових відвідувачів приходить саме з пошукових систем. Тому важливо знати деякі особливості найбільш популярних з них.
УКРАЇНСЬКА ПОШУКОВА СИСТЕМА "МЕТА"
Українська пошукова система "МЕТА" є найвідомішим проектом компанії - ЗАТ «МЕТА» - розробника пошукових і інформаційних рішень. Сьогодні "МЕТА" — один з найбільш відвідуваних українцями сайтів і найбільший рекламний майданчик України.
«Мета.ua» – проект український, він створений і працюватиме тільки для України.
А технології, які були створені в процесі роботи, цілком можуть бути використані в інших країнах.
Пошукові технології компанії працюють у внутрішніх мережах Верховної Ради і кабінету міністрів України, на сайтах національного банку України, фонду Разумкова, сайті Віктора Ющенка.
За 2005 рік аудиторія збільшилася більш ніж в два рази.
«Мета» – це безкоштовний сервіс, який не має ніяких зобов'язань перед власниками сайтів і не гарантує «правильного» місця видачі.
Нові сервіси пошукової системи "МЕТА" можна поділити на три типи: пошукові, інформаційні і комунікаційні.
З пошукових сервісів хочеться відзначити «Метановини». Це найпопулярніший розділ після великого пошуку і каталогу. Зараз там збираються новини від більше як 200 українських інтернет-джерел, близько 10 000 новин в день. Весь цей масив в режимі реального часу індексується, групується по темах і стає доступним для пошуку.
«Пошук рефератів». Практично єдиний сервіс в СНД, що дозволяє шукати не тільки по назві і опису, але і по всьому тексту. В період сесій і іспитів студенти і школярі активно користуються цим сервісом.
З останніх пошукових проектів – інтерфейс до бази законодавства України, що розроблено спільно з апаратом Верховної Ради. У базі більш як 80 000 різних юридичних документів. Автоматичний переклад запитів дає можливість задавати запит на російській або українській мовах.
З інформаційних сервісів цікавими є «Карти» і «Розклади потягів». В «Картах» зібрано найбільшу кількість карт по містах і областях України, що є доступними в Інтернеті, а «Розклади» – є найповнішими та найточнішими.
Комунікаційні сервіси – форум, який став найбільшим українським неполітичним форумом. Поштовий сервіс розроблявся значно пізніше за тих, що є зараз на ринку, тому в ньому вдалося обійти відомі недоліки і він вийшов зручним і функціональним. Пошта зараз самий швидкозростаючий сервіс на «Мете».
Пошуковому сервісу доводиться збільшувати потужність одночасно в двох площинах – з одного боку збільшується кількість запитів, з іншої - зростає об'єм індексу. З схожими проблемами працює всього декілька компаній в світі, і тому на вирішення технічних проблем, пов'язаних з швидким зростанням витрачається багато зусиль. Впроваджено і відпрацьовано технологію, що дозволяє швидко масштабувати систему, Мета може без проблем збільшити розмір індексу і обробити число запитів на порядок більше.
З останніх вдосконалень – «перевірка» правопису в запитах і додавання нових форматів документів – doc, pdf, xls, ppt.
«Повільна індексація» - це вже легенда, яка залишилася у минулому. Черги на розміщення в каталог зараз немає, бо технічних потужностей вистачає. Якщо сайт через 4-5 днів після додавання в каталог не потрапив в індекс, це означає, що він є або недоступним, або не піддається індексації. Окрім цього є спеціальний кластер, документи в якому оновлюються двічі у день.
ПОРАДИ ПО ПОШУКУ
Пошукова система "МЕТА" надає цілий ряд сервісних можливостей, які дозволяють вести більш прицільний пошук. Проте, пошукова система - тільки інструмент, і головний внесок в швидке отримання точних результатів робить користувач, коли формулює свій запит.
Нижче наведено перелік пошукових прийомів, які дозволять ефективніше організувати пошук і оперативно знайти те, що потрібне.
СКІЛЬКИ СЛІВ ВИКОРИСТОВУВАТИ В ЗАПИТІ
За статистикою користувачі зарубіжних пошукових систем використовують в середньому 1,5 слова в запиті. Наші користувачі більш "багатослівні" -- 2,5 слова на один запит.
В тому випадку, якщо потрібна загальна інформація, що має певне відношення до теми, достатньо одного слова. Напевно серед декількох сотень документів, які видасть Мета буде документ, який відповідає темі пошуку. Проте, де буде цей документ -- у першій десятці результатів або десятій десятці -- справа випадку.
Щоб отримати підбірку результатів, яка буде точніше відповідати темі запиту і попутно заощадити час на переглядання відповідей пошукової машини краще шукати відразу за декількома словами, що характеризують запит детальніше.
ЯКІ СЛОВА ВИКОРИСТОВУВАТИ В ЗАПИТІ
Основне смислове навантаження в мові мають імена іменники. Такий стан речей наочно виявляється, коли автор web-сторінки прописує ключові пошукові слова (метатеги), які потім використовуються багатьма пошуковими машинами (Метой зокрема) для індексування і пошуку. Основна маса цих ключових слів -- це імена іменники. Значно рідше використовуються імена прикметники, і зовсім рідко дієслова.
Імена прикметники в запиті -- просто незамінні, якщо користувач захоче знайти в Інтернет саме "голландський сир", з "баварським пивом" в "нічному клубі".
Дуже ефективний засіб для швидкого отримання точних посилань -- це використання рідкісних слів. До таких слів можна віднести спеціальні терміни, назви місцевості, організації, імена людей і інше. Наприклад, полівінілхлорид, Пномпень, УКРНИИЛХА, Лорак і т.п. Використання точних слів відразу "занурює" в потрібну тематику.
БАГАТОМОВНІ ЗАПИТИ
За статистикою Мети велика частина запитів поступає російською мовою. При цьому пошукова база Мети містить документи на російській, українській та англійських мовах.
Подібна багатомовність задає свої особливості пошуку на Мете. Наприклад, для того, щоб отримати повний список сторінок, що мають відношення до освіти, необхідно крім слова "освіта" задіяти також слова "образование" і "education". Якщо цікавить повнота пошуку -- то це найбільш короткий шлях, щоб отримати посилання на весь масив існуючих документів.
Звичайно, великий масив відповідей міститиме однакову інформацію, яка просто представлена на різних мовах. Проте, за дослідженнями, значна кількість сторінок не перекриваються, тобто містять інформацію, яка потрапляє в список результатів тільки при запиті на певній мові.
РОСІЙСЬКО-УКРАЇНСЬКІ ЗБІГИ
Однакове написання різних по сенсу слів (омонімія) при пошуку за ключовими словами може привести до появи в списку відповідей досить несподіваних результатів. Наприклад, по слову "лист" додатково до омонімії російської мови: "лист каштана" і "лист бумаги", при пошуку на Мете додається ще значення "лист -- письмо" з українського. Тобто крім омонімії в російському і українських мовах окремо, з'являється ще російсько-українська омонімія: приклад ружья -- приклад перекладу, свято перемоги -- свято верить, важкий стан -- прокатный стан, Влада народу -- позвать Влада і т.п.
Частково зняти подібну неоднозначність можна за допомогою оператора нормальної форми (поставити перед "підозрілим" словом в запиті знак оклику). Якщо ж використовувати пошук по фразі, омонімія мови практично не впливає на видачу результатів пошуку.
КЛЮЧОВА ФРАЗА
У своїй промові люди використовують безліч стійких виразів, словосполучень, Творці інтернет-сторінок користуються такими ж поєднаннями слів в своїх документах, і тому, запит з використанням стійких фраз і виразів, що відносяться до теми пошуку -- один з могутніх способів швидко отримати добротну підбірку результатів.
Для пошуку в подібних випадках потрібно використовувати лапки (дужки) або оператори відстані, потрібно шукати не слова, а словосполучення. Наприклад, по запиту Век живи - у лапках Мета з великою точністю видасть сторінки, де міститься прислів'я "Век живи -- век учись" і її варіації, при цьому в короткій анотації ресурсу підсвічуватиметься саме ключова фраза. Запити по фразі "Комп'ютерна периферія", "курс валют", "прайс-лист" і т.п. значно скорочують загальне число знайдених документів і дозволяють уточнити пошук.
КОНЦЕПТ ЗАПИТУ
У найзагальнішому вигляді концепт -- це сенс, який вкладається в запит. Питання в тому, яким чином передати те, що хочеться відшукати в ключових словах запиту? Можна спробувати пошукати інформацію в лоб -- просто ввести ключові слова, які відповідають запиту. Як правило, цього достатньо. Якщо ж результатів пошуку немає зовсім або вони є не точними, то потрібно спробувати переформулювати запит (т.е. використати інші ключові слова, синоніми, які відповідають сенсу пошуку).
Можливим є і інший підхід. Документи, які містять потрібну інформацію, можуть не бути присутніми в індексі Мети, проте, вони ймовірніше є десь в українському Інтернеті. Залишається тільки дістатися до них, використовуючи більш загальні за сенсом категорії, які містять ключові слова.
Наприклад, якщо потрібно конкретний український закон, то краще шукати сервери, що присвячені українському законодавству, якщо ж поштову адресу певної організації -- краще спробувати знайти Жовті сторінки і т.д.
ЯК СКЛАСТИ ЗАПИТ
Пошукова система МЕТА дозволяє шукати по всьому українському Інтернету, а також по Реєстру українських сайтів.
ПОШУК В ПОВНОТЕКСТОВІЙ БАЗІ ДАНИХ
Повнотектовий пошук відбувається з врахуванням російської та української морфології. Це означає, що незалежно від граматичної форми ключових слів, будуть отримані документи, які містять шукані слова у всіх формах. Наприклад, за запитом глубокие донья будуть знайдені документи, що містять слова глубокое дно, за запитом рушник вишиваний - документи, що містять слова вишиваному рушникові і т.п.
Пошуковик має наступну особливість: у багатослівних запитах система не ігнорує так звані "стоп-слова". Більшість пошукових систем при пошуку їх ігнорують, тобто, при запиті крем від загару слово "від" буде проігноровано і серед результатів будуть документи із словосполученням "крем для загару". "META" видасть документи, які точно співпадають з запитом.
Щоб покращити пошук можна використовувати ряд службових операторів
ЛОГІЧНІ ОПЕРАТОРИ
| Оператор |
Опис |
| + |
Логічне І. Даний оператор є за замовченням і діє першим, тобто запит українські реферати є рівнозначним до запиту українські + реферати. |
| - |
Логічне НІ дозволяє виключити із списку результатів документи, в яких міститься слово, що йде після оператора. Наприклад, за запитом: кавовий напій - кава, будуть знайдені тільки ті документи, в яких є слова кавовий напій, але немає слова кави. |
| | |
Логічне АБО дозволяє знайти документи, які містять хоча б одне слово в запиті. Наприклад, за запитом: казаки | козаки будуть знайдені документи, які містять або слово казаки, або слово козаки. |
Порядок дії логічних операторів можна задавати круглими дужками ( ).
Наприклад, по запросу харківскі | київські підприємства виводяться документи, що містять або слово харківські, або одночасно слова київські та підприємства, оскільки оператор + діє першим. Якщо ж необхідно знайти документи, в яких зустрічаються слова харківські підприємства або київські підприємства, запит повинен бути таким: (харківські | київські) підприємства.
Окрім логічних виразів можна визначати відстань між словами запиту.
| Оператор |
Опис |
| "..." |
Подвійні лапки дозволяють знаходити точне словосполучення, що в них вказано. При цьому фіксується граматична форма слів, тобто за запитом "погода в Криму" будуть знайдені документи, в яких міститься таке саме словосполучення, - погода в Криму. |
| {...} |
Фігурні дужки дозволяють знаходити словосполучення, що є близькими до вказаного в них, тобто на відміну від попереднього оператора за запитом {погода в Криму} будуть знайдені документи, що містять наступні словосполучення: "погода в Криму", "погоді в Криму", "погоди в Криму", тобто граматична форма слів в даному випадку не фіксується. |
| [n, ...] |
Цей оператор використовується в тому випадку, якщо необхідно обмежити відстань між словами запиту. Наприклад, за запитом [5, мобільний телефон] будуть знайдені тільки ті документи, в яких слова мобільний і телефон розташовані у фрагменті тексту, що не перевищує 5 слів. |
Передбачені також оператори, що дозволяють обмежити область пошуку певним полем документа.
| Оператор |
Опис |
| Title |
Даний оператор дозволяє шукати тільки за назвою документа. Наприклад, за запитом: title(прайс-лист) будуть знайдені ті документи, в заголовку яких міститься прайс-лист, за запитом title("дошка оголошень") будуть знайдені документи, які містять в заголовку словосполучення дошка оголошень. |
| Heading |
Даний оператор дозволяє проводити пошук по назвах розділів документів. Наприклад, за запитом: heading(бізнес-план) будуть знайдені документи, що містять бізнес-план в полі heading документів. |
ПОШУК ПО РЕЄСТРУ УКРАЇНСЬКИХ САЙТІВ
Як і при повнотекстовому пошуку, пошук по реєстру ведеться з врахуванням російської, української і англійської морфології.
За замовченням пошук ведеться по повнотекстовій базі даних, для пошуку по Реєстру, слід поставити прапорець "шукати в Реєстрі".
Можна обмежити область пошуку окремою темою або регіоном. Для цього необхідно перейти у відповідну тематичну/регіональну рубрику і поставити прапорець "шукати в розділі:" або "шукати по регіону:", при цьому пошук буде вестися по повнотекстовому індексу. Якщо ж поставити ще один прапорець - "шукати в Реєстрі", то пошук буде проведено тільки по описах сайтів в даному розділі або регіоні.
ОПИС ЗАРУБІЖНИХ ПОШУКОВИХ СИСТЕМ
Більше як 80% всього пошуку в Інтернеті доводитися на 3 основні системи: Google, Yahoo!, MSN.
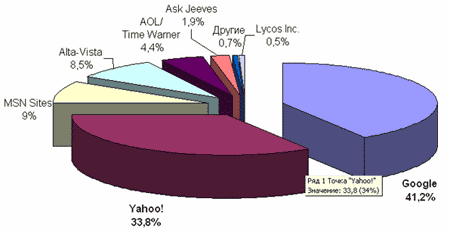
З невеликої компанії, яка заснована у вересні 1998 року Ларрі Пейджем і Сергієм Бріном, Google перетворилася на найбільший галузевий концерн, що пропонує послуги простого і швидкого пошуку інформації в Інтернеті по більш ніж 8 млрд. мережних адрес, плюс множина інших, не менш цікавих сервісів. За ці роки багато що змінилося, але незмінною і зростаючою залишилася динаміка розвитку Google. Особливо вражає успішне і послідовне зростання компанії на тлі поголовного краху, що зачепів в минулі роки більшість дот-комів.
Нині феноменальний успіх Google пов'язують не лише з вибраною бізнес-моделлю і вдалим напрямом діяльності. Карколомний успіх компанії не був би досягнутий без тонкого підбору співробітників і вмілого керівництва. З серпня 2001 року на посту CEO компанії знаходиться Ерік Шмідт, якій перейшов в Google з Novell і поставив за головну мету збільшення капіталізації за рахунок виходу на нові ринки. Минулі роки підтвердили правильність вибраної стратегії і тепер Google є тим, чим є – близько 5 тисяч співробітників у всьому світі, бренд, що відомий без коментарів в будь-якому куточку земної кулі.
Бренд Google було введено як співзвуччя математичному терміну Googol (гугол), придуманому Мілтоном Сироттой, племінником американського математика Едварда Каснера. Він позначає одиницю з сотнею нулів і чудово ілюструє невичерпні можливості Інтернету, які компанія Google постійно систематизує і організовує, полегшуючи доступ до різних даних.
Спочатку була поставлена мета по організації всієї світової інформації, щоб зробити її максимально доступною і корисною для кожного відвідувача Інтернету. Для цього засновники компанії Леррі Пейдж і Сергій Брін розробили новий алгоритм пошуку. Ідея створення універсального пошуковика і стала запорукою нинішнього успіху компанії. Більш того, в нинішньому своєму втіленні пошуковий движок доступний не лише з головної сторінки Google: можна вести пошук через панель інструментів Google, через Google Deskbar в панелі завдань Windows без відкривання браузера, а також з різних мобільних платформ, включаючи телефони в режимах WAP та І-mode.
Оскільки пошуковик Google є безкоштовним, основний дохід компанії складається з надання рекламодавцям можливості поширювати рекламу, що є релевантною до інформації на даній сторінці. Тисячі рекламодавців використовують програму Google AdWords для просування своїх товарів і послуг за допомогою цілеспрямованих оголошень, тисячі менеджерів сайтів використовують Google AdSense для показу оголошень, що є релевантними до змісту сайтів.
Від початку розробники Google відмовилися від типового використання потужностей декількох серверів, продуктивність яких зменшується при пікових навантаженнях, і почали використовувати можливості розподілених у мережі комп’ютерів.
Пошуковий движок Google проводить серії одночасних розрахунків тривалістю частки секунди і використовує технологію PageRank для вивчення всієї структури посилань Інтернету та об'єктивного визначення найважливіших сторінок шляхом розрахунку рівняння з більше як 500 змінними і 2 мільярдами термінів. Пошуковик Google аналізує якісний зміст сторінок - шрифти, підрозділи, точне місцеположення кожного слова, плюс зміст сусідніх сторінок для забезпечення максимальної релевантності результатів пошуку.
В компанії Google створено технологію пошуку для бездротових пристроїв з моментальним перетворенням HTML у формати для режимів WAP, І-mode, J-SKY і EZWeb.
Результатом багаторічного розвитку пошукової системи Google стала поява національних пошукових сервісів: підтримується різномовний інтерфейс і алгоритму пошуку адаптуються до локальних особливостей. Коли пошуковий сервіс Google стартував в Китаї, то, не дивлячись на численні складнощі, пов'язані з своєрідним трактуванням свободи слова китайськими властями (Google.com не доступний китайським користувачам приблизно 10% часу; Google News зовсім не працює, Google Images доступний лише час від часу), сервіс працює і набирає популярність.
Google забезпечує пошук по гіпертекстових документах, що знаходяться в різних мовних зонах - українською, російською, англійською, німецькою і ін. Пошукова система Google має власні піддомени для більшості країн, наприклад, для України - google.com.ua, для Росії - google.ru. Це одна з найбільших пошукових баз в світі.
ПЕРЕВАГИ
- Використання механізму PageRank, який відображає "важливість" сайту і впливає на видачу результатів пошуку. PageRank схожий на індекс цитування у Яндекса (теж залежить від кількості і якості посилань на ресурс). Але на відміну від Яндекса, вплив PageRank у Google не настільки значний, тому люди в Google знаходять саме те, що і шукають.
- Google шукає не лише гіпертекстові файли (html), але і файли у форматі PDF, DOC, PostScript, Corel Word Perfect і ін.
- Пошукова система Google має можливість пошуку зображень. При цьому у запиті можна вказати бажаний розмір, глибину кольору, формат файлу.
- На відміну від багатьох пошуковиків, роботи Google індексують всі сторінки, а не лише найголовніші.
- Всі сторінки Google кешує (заносить в свою базу), і дозволяє користувачеві переглядати документ у кеші Google, не відкриваючи його в першоджерелі (що зазвичай є набагато швидше).
- Google дозволяє обрати мову інтерфейсу, мовні зони для пошуку, кількість повідомлень при видачі результатів та ін.
- Користувачі Microsoft Internet Explorer, Mozilla Firefox і Opera можуть встановити собі програму Google Toolbar, яка створює нову панель інструментів, що дозволяє шукати в Google, не заходивши на сам сайт.
- Рядок пошуку в Google можна використати і як калькулятор. Якщо ввести (48-26)*21, Google видасть правильний результат.
СЕРВІСИ GOOGLE
Можливості Google не обмежені лише традиційним "джентльменським набором" пошуковика з розширеними налаштуваннями та новинами. Нижче наведено короткий і неповний список сучасних сервісів Google:
- Google Local - знаходить місцеві підприємства та послуги в Інтернеті
- Google Mac - пошук по сайтах тематики Apple/Macintosh
- Google’s University Search - пошук по університетах
- Google Linux - пошук по сайтах тематики Linux
- Google GOV - пошук по всіх державних (*.gov) і військових (*.mil) сайтах
- Froogle - пошук товарів/продукції
- Google Options – опції
- Google Map Site - карта сайту
- Google Features - перелік різноманітних особливостей
- Google Microsoft - пошук по сайтах Microsoft
- Google Labs – сервіси
- Hacker Style Google - у оригінальному стилі
- Google BSD - пошук по BSD-сайтах
- Google Наоборот - google в дзеркальному відображенні
- Google Schoolar - пошук серед статей, книг, оглядів наукової літератури та підручників
- Google Firefox - для фанатів Mozilla Firefox
- Google Fight - поєдинок: потрібно ввести два слова, і пошуковик покаже яке з них посилається на більшу кількість сторінок
- Google Suggest - можливі варіанти того, що потрібне, з показом кількості сторінок по даному запиту
- Cheatoogle - пошук по читам і кодах до ігор
- Google Easter - пасхальний кролик
- Gmail - пошта від Google
- Video google - пошук відео
- Google для мобильников и КПК - міні-версія для зручної роботи з мобільних телефонів і КПК
- Mobie Google - сервіс для мобільного зв’язку
- Google Fan Logos - сайт з логотипами на тему Google
- Google Hiliday Logos - святкові логотипи
- Офіційні та Неофіційні - логотипи Google
- Google April Fools - пошук про все, що пов'язане з днем дурнів
- Google Maps - пошук по картах
- Google Blog - офіційний блог Google
- Google News - новини від Google
- Google Print - пошук Google по мільйонах оцифрованих книг бібліотек Гарварду, Стенфорда, Оксфорда, Мічігану, а також з Нью-йоркської Публічної бібліотеки
- Google Earth - програма для огляду Землі з космосу
- Can’t find on google - сайт із переліком запитів, у відповідь на які видається не те, що потрібне
- GoogleGulp- напої від Google
- Uncle Sam - "патріотичний" пошуковик
- Blogsearch - пошук по блогам і ЖЖ
- Google Webmasters Guidelines - інформація та поради Google для веб-розробників
- Google Reader - Google Reader
- Google Code - для кодерів, відкриті ісходники і т.д.
- Google VPN - безкоштовний VPN-сервіс від Google
- Google Alerts - відстежує появу нових сторінок на пошуковий запит і повідомляє про це на e-mail
- Google Answers- можна задати запитання, вказати суму винагороди за відповідь і дочекатися відповіді
- Personalized Google Search- пошук з врахуванням налаштувань та потреб користувача
- GoogleStore- магазин з аксесуарами в стилі і з логотипами Google
- Google Trade Catalogs - каталог товарів
- Google Personalize Homepage - підлаштування пошуку та зовнішнього вигляду Google під себе ;)
- Google Base - база даних від Гугл, можна завантажити будь що
І це далеко не повний перелік можливостей, сервіси Google постійно поповнюються, а їх якість вдосконалюється.
Yahoo було засновано в 1994, і на сьогоднішній день це найстаріший і якнайповніший каталог Інтернет-ресурсів.
Ця неймовірно популярна система, що обслуговує мільйони запитів щодня, зародилася як проста колекція закладок, яку поповнювали всього 2 людини - Девід Філо і Джері Янг.
Yahoo є найпопулярнішим пошуковим засобом і секрет його успіху Yahoo криється в людях. Над складанням та редагуванням вмісту каталогів Yahoo працюють понад 150 редакторів. Yahoo має базу даних в більш, ніж 1 млн. проіндексованих сайтів. Також, у разі браку власної бази даних, Yahoo використовує базу даних Google (до липня 2000 року Yahoo користувався базою даних Inktomi).
AltaVista почала надавати свої послуги в грудні 1995 року і на сьогоднішній день є однією з найбільш великих пошукових систем (за кількістю проіндексованих сторінок). Як особливість пошуковика можна зазначити можливість пошуку за ускладненими критеріями відбору. AltaVista пропонує додаткові послуги у вигляді пошуку по каталогах (взятими з Open Directory and LookSmart), а також службу під назвою "Ask AltaVista" ("запитай AltaVista"), результати якої беруться з Ask Jeeves. На даний час AltaVista є власником пошукової системи Raging Search.
Пошуковик розроблено та запущено компанією Microsoft у 1997 року.
На відміну від інших пошукових систем, раніше у MSN ніколи не було власного павука або каталога. З 1997 року для видачі результатів пошуку використовувалися різні бази даних, такі як: Yahoo!, LookSmart, Altavista, DirectHit, Inktomi і RealNames.
Тільки з початку 2005 року MSN запустив бета-версию власного пошукового алгоритму. Користувачі MSN Search можуть здійснювати пошук як по всьому Інтернету, так і по окремих тематичних категоріях, у тому числі і по енциклопедії Microsoft Encarta.
Новий движок містить можливість локалізованого пошуку (Near Me) - система здатна автоматично визначати місцезнаходження користувача за IP-адресою його комп'ютера.
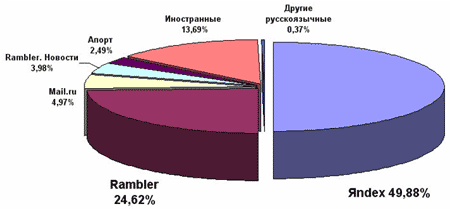
ОПИС РОСІЙСЬКИХ ПОШУКОВИХ СИСТЕМ
В Рунеті основними є пошукові системи Яndex, Rambler та Mail.ru На діаграмі представлена питома вага різних пошукових машин Рунету.
Yandex виконує пошук по словяномовній частині Інтернету з урахуванням морфології словянських мов. Маючи могутній механізм підбору сайтів під запити, ця пошукова машина допомагає знайти найбільш відповідні веб-сторінки. Яндекс щодня переглядає сотні тисяч веб-сторінок у пошуках змін або нових посилань, і їх база постійно зростає.
Слово "Яndex" означає "Мовний index", або, якщо по-англійськи, "Yandex" - "Yet Another indexer". За 10 роки публічного існування Яndex виникали і інші тлумачення. Наприклад, якщо в слові "Index" перекласти з англійського першу букву ("I" - "Я"), вийде "Яndex".
Офіційно пошукова машина Yandex.Ru була анонсована 23 вересня 1997 року на виставці Softool. Вже тоді пошуковик мав певні переваги - можливість перевірки документів на унікальність, облік морфології словянських мов, можливість пошуку з врахуванням відстані (наприклад, при пошуку точного словосполучення). Основною відмінною рисою Yandex є ретельно розроблений алгоритм оцінки відповідності відповіді запиту (релевантності), який враховує не лише кількість слів запиту, знайдених у тексті, але і "контрастність" слова (його відносну частоту для даного документа), відстань між словами, і положення слова в документі.
Згідно даних глобальної статистики Рунету, сьогодні більше 50% пошукового трафіку генерується саме цим пошуковиком (для порівняння, на долю Rambler'a доводиться близько 20%, і ще менше - на долю Google'a).
Реєстрація відбувається за адресою http://yandex.ru/addurl.html. В Яндекса достатньо швидкий пошуковий робот. Завдяки ньому реєстрована сторінка з'явиться в пошукових результатах протягом 2-4 годин. Але це лише первинна індексація. Після повної індексації, вона може зникнути з пошукових результатів, якщо пошуковий робот визнає її за спам. Тому положення web-сторінки в результатах пошуку потрібно відстежувати до тих пір, поки не пройде повна індексація. Перелік результатів може мінятися залежно від завантаженості серверів, оскільки база даних Яндекса має кластерну структуру і рознесена на декілька серверів.
Яндекс любить документи середніх розмірів, насичені текстом (статті і т.п.). Слід помірно повторювати ключові слова. Ключові слова можна писати в описі, але вага слів у цьому тегу є нижчою. Добре індексуються сторінки, що створено за допомогою скриптів .cgi, .php. Це стосується гостьових книг, форумів і т.п. Для індексації решти (окрім головної) сторінок сайту потрібно приблизно 2 тижні.
Хороших позицій допомагають досягати ключові слова в мета-тегах, де варто зазначати слова, які зустрічаються в тексті сторінки. Мета-теги, використовуються також і для видачі опису сторінки в результатах пошуку. Це потрібно враховувати при його складанні, оскільки, користувач по цьому опису приймає рішення відвідати вас, чи ні. Важливо розміщувати ключові слова і в тегу "title", заголовках (h1-h6), змісті сторінки, "ALT"-тегах.
Для визначення релевантности Яндекс використовує Зважений Індекс Цитування, який впливає на рейтинг в результатах пошуку. Звичайний Індекс Цитування використовується тільки при сортуванні сайтів в каталозі Яндекса.
Цей пошуковик займає сьогодні друге місце серед пошуковиків Ренета. Він був першою пошуковою програмою, що створено спеціально для російського Інтернету програмістом компанії Stack Ltd Дмитром Крюком у 1996 році. Слово "Rambler" перекладається як «гуляща людина», «бродяга» по Інтернету.
Rambler постійно вдосконалює свій пошуковий алгоритм. Проводяться роботи по оптимізації роботи системи для точності та актуальності пошуку. Як і більшість російських пошукових машин, Rambler враховує морфологію російської мови. При видачі результатів вплив має положення сайту в рейтингу Rambler's Top100. Rambler індексує сайти в зонах ru .su, .ua, .by, .kz, .kg, .uz, .ge, а також славяномовні сайти в доменах .com, .net або .org.
На сьогодні Rambler є в величезним інтернет-холдингом, до складу якого входять портал Рамблер, новинна інтернет-газета Лента.ру, медичний сайт Doctor.ru, онлайновий клуб батьків Mama.ru, картографічний сервіс NaKarte.ru, телекомунікаційний підрозділ "Рамблер Телеком".
На Рамблері реалізовано розумну систему, яка виводить в результатах пошуку слова, які є синонімами запиту. Ще однією функцією системи є видача контекстної реклами не лише за конкретними ключовими словами, але і за фразами, що тісно пов'язані з ними.
Реєстрація знаходиться за адресою http://www.rambler.ru/doc/add_site_form.shtml. Не реєструються сайти в доменах .com, .net, або .org. Якщо ж зміст сайту з цих зон має відношення до російськомовного Інтернету, то користувач має відправити лист на search.support@rambler-co.ru з проханням проіндексувати сайт.
Рамблер (на відміну від інших пошукачів) вміє витягувати гіперпосилання з об'єктів Macromedia Flash. Якщо сайт має заставку або навігаційні панелі, що виконані з використанням цієї технології, Рамблер обробляє їх, знаходить адреси всіх сторінок сайту і індексує весь сайт. Тексти flash-об'єктів не індексуються. Для сайтів, які цілком складаються з flash-об'єктів, рекомендується створити HTML-копію і зареєструвати її в пошуковій машині. Роботи Рамблера також справляються з конструкціями фреймів.
Роботи Рамблера ігнорують більшість мета-тегів. Коментарі в документі роботи Рамблера теж не сканують, але більшої уваги звертають на заголовки і виділення в документі. Базові поняття і ключові для даного сайту слова доцільно включати в наступні HTML-теги (у порядку значущості): "title", "h1"..."h4", "b", "strong", "u".
Максимальний розмір документа для роботів складає 200 кілобайт. Документи більшого розміру усікаються до вказаної величини.
Пошукову систему "Апорт!" було розроблено компанією "Агама" за підтримки Intel і вперше продемонстровано в лютому 1996 року на прес-конференції "Агамы" з приводу відкриття "Російського клубу". Тоді вона шукала лише по сайту russia.agama.com.
Найважливішими особливостями першої версії "Апорту" були переклад запиту і результатів пошуку англійською мовою і зворотно, а також відновлення всіх проіндексованих сторінок з власної бази (що надає можливість переглядання сторінок, вже неіснуючих в оригіналі).
До кінця 1999 року було представлено нову версію Апорт - "Апорт 2000", який став першим російським пошуковиком, що побудований на основі видачі результатів по окремо взятих сайтах. "Апорт 2000" практично реалізував дві базові технології американської пошукової машини Google: облік "рангу сайту" (Page Rank), і обробка запиту, орієнтуючись на HTML-код сторінки. Серед недокументованих особливостей - більший пріоритет сайтам, які мають вищу та елітну лігу у каталозі AtRus.
Aport є повнотекстовою пошуковою системою, тобто вона індексує всі слова, які б побачила на екрані людина, що переглядатиме конкретну сторінку. В результаті будь-яке слово з тексту документів може бути критерієм для подальшого пошуку. Апорт також індексує тексти гіперпосилань на документ з інших сторінок, що знаходяться, як всередині сайту, так і за його межами, а також складені (або перевірені) редакторами описи сайтів з каталогу.
Результати пошуку впорядковуються за частотою використання шуканих термінів. Разом з посиланням відображається фрагмент тексту, де зустрічається термін, вказується індекс відповідності до запиту і дата останньої модифікації файлу. "Апорт!" у виданому фрагменті тексту виділяє червоним кольором запитані слова.
Реєстрація сайту в Апорті проводиться із сторінки http://www.aport.ru/addurl.asp. Ця сторінка доступна з будь-якої сторінки Апорту, наприклад, з головної сторінки Апорту. Додавати в пошукову систему Апорт слід російськомовні сайти, а також сайти, що мають безпосереднє відношення до російського Інтернету. У разі відмови в автоматичному додаванні сайту можна звернутися з проханням про додавання сайту за addurl-nr@aport.ru.
З моменту додавання сайту в Апорт до моменту його появи в пошуковій базі проходить від двох-трьох днів до двох тижнів.
При перегляданні вмісту сервера для індексування Апорт обов'язково перевіряє файл ROBOTS.TXT. Отже можна його використати, щоб обмежити 'діяльність' Апорту на своєму сервері. Апорт за умовчанням не індексує динамічні документи, в адресах яких зустрічається символ '?'.
Для документів HTML, окрім основного тексту документа індексуються також: заголовок документа "TITLE", ключові слова "KEYWORDS", описи сторінок "DESCRIPTION" і підписи до картинок "ALT". Апорт пропонує декілька варіантів направленої реклами http://www.aport.ru/adv, проте немає можливості купити вищі місця для свого сайту в результатах пошуку.
Ключові слова не мають визначального значення при визначенні релевантности документа. Але розумне використання цього тега рекомендується.
На відміну від багатьох інших пошукових систем, Апорт не застосовує спеціальних санкцій до сайтів, що намагаються обдурити пошукову систему за допомогою спаму, але досягнути подібним чином бажаного результату не вийде. Тому не варто писати невидимі тексти, набирати сотні ключових слів, що не мають жодного відношення до змісту документа і т.д.
Ось перелік основних критеріїв, які Апорт враховує при сортуванні сайтів: густина ключових слів, відстань між ключовими словами в тексті документа, місце, де зустрічаються пошукові слова (заголовок, опис, мета-тег і т.п.), зовнішній вигляд шрифту, яким набрані ключові слова (розмір, грубість, колір), кількість посилань з Інтернету на даний документ, використання ключового слова в тексті посилань з Інтернету на даний документ. Остаточний відсоток відповідності документа до запиту будується як певна функція від всіх цих показників.
З ЧОГО ПОТРІБНО ПОЧИНАТИ ПОШУК?
По-перше, визначитися з метою пошуку. При цьому потрібно концентруватися не лише на самій меті, але і на тому, що може її супроводжувати.
У ідеалі процес пошуку повинен виглядати приблизно так. Спочатку робиться загальний запит, отримується відповідь з результатами пошуку, в якому потрібно виділити описи більш-менш відповідних посилань. Потім необхідно додати до запиту загальні ключові слова, які є в описі потрібних посилань і повторити процес. Якщо все робити правильно, то кожен запит повинен наближати до потрібної інформації. Користувач має бути своєрідним зворотним зв'язком, з кожним кроком зменшуючи невідповідність між потрібною інформацією і тим, що видає пошукова система.
Розглянемо невеликий приклад - необхідно знайти розклад потягів що проходять через Київ. Як загальний запит можна так і спробувати "запитати" пошукову систему: розклад всіх потягів що проходять через київ. Проте, по такому запиту, наприклад, Яндекс, знаходить лише розклади потягів, що проходять через Львів, Тернопіль, але Києва серед результатів пошуку не видно. Це у жодному випадку не означає, що цієї інформації в базі пошукової системи немає, просто запит був сформульований не дуже вдало.
Річ у тому, що будь-яка пошукова система прагне знайти сторінки, на яких знаходиться максимальна кількість слів з запиту, більш того, якщо ці слова слідують один за одним, то такі сторінки будуть виведені першими. Тобто, наприклад, якщо в тексті сторінки зустрічається фраза розклад всіх потягів, що проходять через Львів, то за відсутності такої ж фрази розклад всіх потягів, що проходять через Київ система визначить, що вони мають 5 загальних слів, тобто з великою ймовірністю сторінка, що містить цю фразу підійде, хоча це і не так. Тому потрібно такий запит скоректувати, прибравши всі слова-паразити і залишивши лише слова, які точно характеризують вашу потребу. Словами-паразитами є слова всіх, що проходять, через, які можуть зустрічатися на яких завгодно сторінках. Задавши скорегований запит розклад потягів київ, результат буде кращим.
Саме так зараз врешті-решт поступають переважна більшість користувачів, проте, для того, щоб навчитися швидко і ефективно знаходити потрібну інформацію, просто скоректувати запит в більшості випадків недостатньо. Необхідно ще ознайомитися з декількома дуже корисними, а іноді просто незамінними операторами мови запитів пошукової системи. Ці оператори не тільки істотно полегшать роботу, але і допоможуть знаходити таку інформацію, яку за допомогою простих запитів знайти абсолютно неможливо.
Що таке оператори пошукової системи і для чого вони потрібні? Оператори дозволяють не тільки точніше сформулювати запит, але і вибирати, на яких сторінках здійснювати пошук і навіть в яких їх елементах, наприклад, заголовках, ключових словах або посиланнях. Розглянемо оператори, що є загальними для всіх пошукових систем.
Перший оператор - оператор строгої відповідності, як правило, в сучасних пошукових системах це лапки "". Поєднання слів, які вказані в лапках, будуть враховані системою як єдине ціле, а також задається порядок проходження слів один за одним. Наприклад, за запитом комп'ютерні журнали можна отримати в результатах пошуку сторінки із словами, що згадуються відособлено, тобто на одній сторінці може бути слово комп'ютерні, на іншій - журнали і т.д. Конструкція "комп'ютерні журнали" в лапках примушує пошукову систему відкинути всі зайві сторінки і показувати лише ті, на яких ці два слова йдуть один за одним.
Наступні важливі оператори - оператор обов'язкової наявності слова "+" і оператор обов'язкової відсутності слова "-". Наприклад, якщо потрібно знайти сайт журналу ЧІП, достатньо до запиту "комп'ютерні журнали" додати +чіп: "комп'ютерні журнали" +чіп. Якщо ж потрібно вивести всі журнали, окрім Чіпа, потрібно ввести "комп'ютерні журнали" -чіп.
Використовуючи ці три прості оператори, вже можна істотно скоротити витрати на час пошуку інформації.
Часто є потреба, щоб шукані ключові слова були присутні в межах одного документа. Для цього необхідно використовувати оператор логічного І AND. Проте, у всіх пошукових системах це можна зробити, якщо поставити звичайний пропуск. Наприклад, запити комп'ютерні журнали і комп'ютерні AND журнали, як правило, нададуть однаковий результат. Оператор логічного АБО OR дозволяє знайти хоча б одне слово із запиту. Наприклад, за допомогою запиту комп'ютерні OR журнали можна знайти документи, в яких зустрічається або слово комп'ютерні, або слово журнали.
З мовами запитів конкретної пошукової системи можна ознайомитися в її розділі допомоги. Багато з них мають власні додаткові оператори.
ПРЕДСТАВЛЕННЯ ШУКАНОГО ДОКУМЕНТА ЯК ОБРАЗУ
Пошук можна істотно спростити, уявивши собі образ сторінки, що містить потрібну інформацію. Існують загальноприйняті правила, яких притримуються практично всі сторінки Інтернет. Основне і головне правило: заголовок кожної сторінки стисло і точно характеризує її вміст. Відшукати, наприклад, певну книгу в електронному вигляді дуже просто. Звичайно, можна спробувати її знайти, якщо задати в пошуковій системі прізвище автора і назву і зрештою знайти її, але тоді витрачається багато часу на переглядання абсолютно даремних сторінок із згадкою даної книги або автора, але без її електронної копії.
На допомогу тут знов приходять розширені можливості пошуку, використовуючи які, можна відшукувати потрібну інформацію прямо в заголовках сторінок.
Простій приклад - потрібно знайти, припустимо, книгу Паоло Коельо "Алхімік". Спершу складаємо образ потрібної сторінки - швидше за все, в її заголовку можуть знаходитися і прізвище автора, і назва твору. Далі потрібно з'ясувати, як включити розширені можливості пошуку по заголовку в пошуковій системі. Наприклад, в Яндекс для пошуку по заголовках потрібно використовувати конструкцію $title(), таким чином, запит може виглядати як: $title(коельо "алхімік"). Результат перевершує всі очікування - перші 7 посилань, які вивів Яндекс в результатах пошуку, містять потрібні дані.
Шукати так само можна не лише книги, а все, що завгодно. Ще один реальний приклад – потрібно знайти, скажімо, результат фіналу футбольного матчу кубка Іспанії між Реалом і Депортіво. Для того, щоб переконатися в правильності вищевикладених принципів, цього разу використаємо іншу пошукову систему, популярну Google. Для пошуку по заголовках в неї використовується інша конструкція - allintitle. Створюємо образ потрібної сторінки - вірогідно, в заголовку новини повинна бути присутньою фраза "кубок іспанії" і назви команд, що беруть участь, наприклад, мадридський реал в кубку іспанії. В даному випадку запит може виглядати приблизно так: allintitle: реал "кубок испанії". Якщо задати щось подібне до allintitle: реал депортіво "кубок іспанії" і пошукова система показала, що сторінок, які б задовольняли цьому запиту, немає, оператор allintitle можна не застосовувати і пошукати у всьому тексті: реал депортіво "кубок іспанії". Результат в обох випадках вражає - знайдена одна і та ж потрібна сторінка.
Але не лише заголовки корисні при пошуку потрібної інформації. Велику допомогу надає і текст посилань. Будь-який сайт містить певні посилання, які ведуть на його сторінки або сторінки інших сайтів. Кожне таке посилання має власний опис, по значенню сумірне, а часто і більш інформативне, ніж заголовок самої сторінки, на яку вона веде. Адже і в текстах посилань теж можна шукати, та ще як!
Отже, що ж надає текст в посиланнях? Наприклад, потрібно знайти в Інтернеті певний файл, наприклад, викачати останню версію універсального музичного програвача winamp. Створимо образ сторінки. Оскільки програма ця відома, то, ймовірно, існує багато сайтів, на яких є посилання на сторінку, де можна викачати останню версію winamp. Якщо спробувати пошукати в тексті цих посилань, швидше за все одною з перших в результатах пошуку з'явиться потрібна нам сторінка, оскільки решта всіх посилань веде саме до неї. Для пошуку в описах посилань в Google використовується оператор allinanchor, отже, запит можна сформулювати приблизно так: allinanchor: winamp download. Для того, щоб упевнитися у вірності приведеного, можна замість winamp поставити іншу програму - якщо в Мережі на неї є хоч одне посилання, система виведе її першою.
ПОРЯДОК РОБОТИ
- Відкрити пошукові сайти і ознайомитися з їх структурою, налаштуваннями та довідковою системою.
- Провести пошук за ключовими словами та фразами.
- Застосувати для пошуку оператори мови пошуку.
- Ознайомитись з результатами пошуку.
- Порівняти можливості пошукових систем.
ЗМІСТ ЗВІТУ
- Назва та мета виконання лабораторної роботи.
- Організація пошукового сервісу.
- Основні пошукові сайти Інтернет.
- Аналіз результатів пошуку.
- Висновки.
|