
Інтернет з кожним днем все більше нагадує самоорганізоване середовище, що еволюціонує з шаленою швидкістю. І хоча ця система ще не має повноцінного штучного інтелекту, цікаві додатки вже починають користуватися популярністю (наприклад, віртуальні співрозмовники, машинний зір та аудіо інтерфейс).
Розробкою інтелектуальних додатків займаються спільноти, що об'єднані спільними ідеями, цілями та інтересами, які готові витрачати свій час і ресурси на втілення цих ідей. Тому, з кожним днем в Інтернеті з'являється все більше розумних програм, їх функціонал стає все ширше, а відвідувачі перетворюються зі споживачів в активних творців контенту.
Технології штучного інтелекту в IT-індустрії задіяні для численних проектів в цій сфері, вражаюче за масштабами проникнення інтелекту практично у всі області сучасного життя - від медицини, експертних систем і наукових досліджень до промислової робототехніки і безпілотного транспорту. Напрямок машинного навчання і нейронних мереж активно розвивається і вдосконалюється, в ньому задіяні Intel, AMD, NVIDIA, IBM, Google, Facebook, ABBYY, а також тисячі інших компаній-розробників по всьому світу.
Ще 20 років тому штучний інтелект можна було протестувати тільки в крутих лабораторіях або великих компаніях, а сьогодні це доступно для більшості зацікавлених людей і його значне зростання передбачає багато аналітиків.
Інтелектуальна гра Акінатор
 «Акінатор» це Інтернет-додаток, що розроблений двома французькими програмістами в 2007 році. Користувач повинен загадати будь-якого персонажа, а Акінатор його відгадує. Такими персонажами можуть бути як реальні особи, так і вигадані персонажі з фільмів, казок, комп'ютерних ігор тощо.
«Акінатор» це Інтернет-додаток, що розроблений двома французькими програмістами в 2007 році. Користувач повинен загадати будь-якого персонажа, а Акінатор його відгадує. Такими персонажами можуть бути як реальні особи, так і вигадані персонажі з фільмів, казок, комп'ютерних ігор тощо.
Програма виконує наступні вимоги:
- Здатність до навчання. Очевидно, що не можна навчити програму розпізнавати кілька сотень тисяч персонажів шляхом ручного введення відповідей на питання для кожного з них. Альтернатива до цього підходу - вчитися на ходу, користуючись відповідями користувачів.
- Програма толерантна до помилок. Думка користувачів з приводу відповідей на деякі питання може значно різнитися. Простий приклад: палка шанувальниця і звичайний чоловік загадують Олега Винника. На питання «Ваш персонаж сексуальний?» перша, ймовірно, відповість так, в той час як більшість людей буде мати інші відповіді. Однак подібне розходження не повинно заважати .
- Розумний вибір питання. Є багато стратегій, що визначають питання, які потрібно задавати. Наприклад, можна задати взагалі всі або випадкові питання, але до відповіді доведеться йти дуже довго. А можна намагатися вибирати чергове запитання так, щоб дізнатися при відповіді на нього якомога більше інформації. Саме це ми і будемо намагатися робити.
Акінатор задає до 40 запитань. На випадок, якщо він не зміг відгадати загаданого гравцем персонажа він має дві додаткові спроби (в кожній кілька додаткових питань). На кожне питання пропонується вибрати один з п'яти варіантів відповіді: «Так», «Можливо, частково», «Я не знаю», «Скоріше ні, не зовсім», «Ні». Акінатор починає з більш загальних питань, і кожне наступне питання має уточнюючий характер. Таким чином Акінатор фільтрує вибір ймовірних чи невідповідних персонажів.
Один персонаж характеризує множина параметрів, кожен з яких представляє собою вісь (вимір) в багатовимірної системі координат. Поточне задане питання прояснює значення відповідного параметра. Коли значна кількість людей загадує певного персонажа, сукупність їх відповідей (параметрів) для цього персонажа утворює множину точок, локалізованих в певній області щодо даної системи координат. У міру набору статистики, для кожного персонажа утворюється своє скупчення точок (кластер). Персонажні кластери знаходяться на різній відстані один від одного в залежності від того, чим дані персонажі відрізняються.
Наприклад, якщо обидва персонажі - актори, живуть в Америці, старше 50 років, то по цих осях кластери даних персонажів будуть збігатися. Але, якщо один з них лисий, а інший - з шевелюрою, то дані кластери можуть бути легко розділені по осі лисий-нелисий за допомогою питання: "чи задуманий персонаж є лисий?". Після кожного такого питання, Акінатор перевіряє стан точки, утвореної відповідями загадувати, в системі координат питань щодо персонажному кластеру. Якщо за десятком вимірювань видно, що ця точка належить до певного кластеру, а решта кластери досить далеко, Акінатор легко справляється з загадкою.
Однак, часто буває так, що кластери розташовані дуже близько і зливаються. Це може бути, наприклад, якщо обидва вищезазначених актора є лисими і при цьому носять вуса. В цьому випадку Акінатору потрібно шукати додаткові виміри (питання), щоб їх розрізнити. Оскільки люди часто помиляються у відповідях, то кластери, що відрізняються по одній координаті можна легко переплутати, особливо якщо набрана з даного питання статистика недостатня, а питання нерелевантні.
Вдалося Акінатору знайти релевантне питання-вимір, за яким кластери різняться надійно - він вгадав. Не вдалося - з великою ймовірністю він видає помилковий варіант. Оскільки, в процесі навчання програми винаходяться все нові питання (з'являються нові виміри), і для кожного питання набирається статистика (поліпшується точність розрізнення по осях), ефективність вгадування персонажів Акінатор буде постійно зростати.
У разі, якщо Акінатор не відгадав персонажа, то він представляє можливих персонажів, яких він припускав і пропонує ввести назву загаданого персонажа, після чого запам'ятовує всі відповіді, які були задані. Таким чином, кількість персонажів, відомих Акінатор, постійно збільшується. Для більшості користувачів кількість персонажів зазвичай є обмеженою (до 100 персонажів), тому навіть стартової бази цілком вистачає для того, щоб відгадувати більшу частину запитів.
Платформа Google AI
Компанія Google об'єднала передові дослідження, всі проекти Google Research та розробки, пов'язані зі штучним інтелектом та машинним навчанням під одною назвою - Google AI. Google.ai стане базою всіх напрацювань компанії, пов'язаних з ШІ: досліджень, інструментів і розробок на його основі.
На сайті розміщують дослідження від Google і її підрозділу Brain. Крім Google, питаннями машинного навчання займаються університети і приватні лабораторії по всьому світу, і компанія хоче зробити їх дослідження доступними для всіх.
Створення моделей машинного навчання займає дуже багато часу і фінансових ресурсів, але Google.ai націлений на поширення досягнутих результатів, щоб зробити машинне навчання більш доступним.
Вдосконалюється інструмент AutoML, метою якого є вдосконалення нейронних мереж, що спроможні генерувати інші нейронні мережі, а навчання з підкріпленням може застосовуватися у більш складних завданнях.
Експерименти з Google
Компанія Google представила проект AI Experiments, в якому користувачі можуть працювати з нейромережами і алгоритмами машинного навчання, дізнатися, що вони вміють робити і як «бачать» надані їм дані, а також поділитися своїми напрацюваннями в цій галузі.
З 2009 року кодери створили тисячі додатків за допомогою Chrome, Android, AI, Web VR, AR та інших. Сервіс демонструє проекти, а також корисні інструменти та ресурси, щоб надихнути створення нових експериментів. Колекція постійно поповнюється новими додатками, деякі з них надаються для використання чи вивчення.
Сервіс допомагає користувачам розібратися, як працюють основні алгоритми машинного навчання, код будь-якого додатку можна завантажити і вивчити самостійно. У розробників є можливість розмістити на сайті власні алгоритми, щоб отримати зворотній зв'язок або навчити алгоритм.
Розпізнавання малюнків Quick, Draw!
Сервіс Quick, Draw! ( «Швидко малюй!») використовує нейромережу, що розпізнає об'єкти на найпростіших малюнках. За основу взято попередньо навчену нейромережу, яку Google використовує в своєму перекладачі для розпізнавання рукописного тексту. В даному сервісі її завданням є навчитися розпізнавати найпростіші образи, що користувач намагається намалювати.
Розпізнавання малюнка для штучного інтелекту - непросте завдання, наприклад, котика можна зобразити тисячами різних способів, кожен з яких буде моментально зрозумілий людиною. Для полегшення завдання, враховується не лише форма малюнків, а й порядок, в якому користувачі додають штрихи. Наприклад, при малюванні голови кота багато людей спочатку зображують контур, а вже потім додають вуха, вуса, очі та інші деталі.
Для того, щоб нейромережа швидко видавала якісні результати, її треба постійно навчати. Цей процес фахівці Google вирішили перетворити в краудсорсингову онлайн-гру. Користувач має намалювати шість простих об'єктів, на кожен з яких відводиться по 20 секунд. У процесі створення картинки нейромережа намагається вгадати, що на ній зображено. Якщо поставлена задача і здогадки штучного інтелекту збігаються, користувач може перейти до наступного завдання.
По завершенні гри Quick, Draw! додає малюнки користувача в базу даних, тим самим удосконалюючи свої алгоритми, а також надає для кожного з них детальний розбір. Система показує користувачеві, на що його малюнок був схожий, і як той же самий об'єкт малювали інші люди (рис.1).
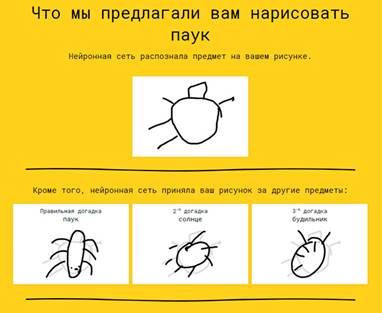
Рис.1. Результат розпізнавання нейромережею малюнку
Ця гра допомагає нейромережі навчатися на багатьох прикладах від численних користувачів. Модель навчання покращується з ростом кількості вгаданих зображень. Всі дані, що створені понад 15 мільйонами гравців залишаються в публічному доступі. Створені логотипи складають унікальний набір даних, який може допомогти розробникам тренувати нові нейронні мережі, допомагати дослідникам бачити, як малювати фігури і допомагати художникам створювати нові форми.
Створення малюнка з ескізів AutoDraw
На сьогодні є багато додатків, що здатними перетворювати рукописний текст в друкарський. Розробники від Google поставити за мету навчити штучний інтелект розшифровувати каракулі і представила додаток AutoDraw, що вміє перетворювати кострубаті закарлючки в малюнки.
Користувач починає малювати певний об'єкт в AutoDraw. Звичайно, малюючи мишею або пальцем, складно створити якісний образ, однак додаток розпізнає, що користувач хоче зобразити. На аналіз зображення йдуть лічені секунди, після чого на верхній панелі з'являються значки з пропонованими картинками і написом «Do you mean» ( «Можливо, ви мали на увазі»). Якщо серед запропонованих об'єктів є відповідний, то після кліку на ньому, криві каракулі перетворяться в малюнок (рис.2).
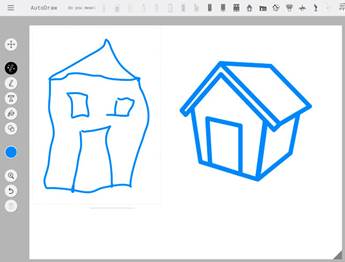
Рис.2. Результат виконання сервісу AutoDraw
Готові малюнки можна переміщати по екрану, розфарбовувати і зберігати для подальшого використання.
PoemPortrets
Сервіс від Google Labs Arts & Culture Lab експериментує на перетині штучного та людського інтелекту - поєднання поезії, дизайну та машинного навчання. PoemPortrets - це автопортрет користувача, на який накладено унікальну поему, що створена штучним інтелектом.
Для роботи сервісу потрібно вказати ключове слово для вірша і зробити селфі. Зазначене слово буде розширено на оригінальні поетичні рядки за алгоритмом, який базується на вивчений мільйонах слів поезії ХІХ століття. Після виконання обчислень користувач отримує унікальний PoemPortrets свого обличчя, на який накладено оригінальні поетичні рядки. Всі створені поетичні рядки в подальшому поєднуються, щоб поповнювати колективну поему (рис.3).
Сервіс не копіює і не переробляє існуючі фрази, а використовує навчальний матеріал для побудови складної статистичної моделі. В результаті алгоритм генерує оригінальні фрази, що імітують стиль того, на чому він навчався. Отримані вірші можуть бути як змістовними так й безглуздими.

Рис.3 Результат виконання сервісу PoemPortrets
Розпізнавання обєктів Giorgio Cam
Сервіс призначений для розпізнавання об'єкту, що фіксується камерою. Нейромережа розпізнає об'єкт, складає вірш за підсумком результату розпізнавання і накладає відповідний музичний супровід. Іноді результат дуже смішний, особливо якщо навести камеру на незвичайні об'єкти (рис.4).

Рис.4. Результат виконання сервісу Giorgio Cam
В даному проекті використовуються програми MaryTTS, Tone.js і Google Cloud Vision API.
Розфарбовування чорно-білих фотографій Colorize
Унікальний проект на основі штучного інтелекту від сінгапурської компанії GovTech, що дозволяє в лічені секунди розфарбувати старі фотографії. В його основі - проект з відкритим вихідним кодом DeOldify. Головною «фішкою» програми є наявність нейронної мережі, яка намагається передбачити значення кольорів для пікселів на основі особливостей знімка. Для навчання штучного інтелекту фахівці використовували набір з 500 тисяч старовинних фото, а також задіяли бібліотеку зображень Google.
За допомогою сервісу легко розфарбувати чорно-білі фотографії, втім додаток добре працює лише з якісними знімками з чітко виявленими елементами. Якщо сервіс не розпізнає об'єкт, то може вийти досить кумедний колірний ефект, найчастіше неприродний (рис.6).

Рис.6. Результат виконання сервісу Сolourise
Сolourise - ідеальне рішення для отримання кольорового зображення швидко, просто і безкоштовно (до 50 фотографій). Час очікування - від 30 секунд.
Покращення якості фотографій Let's Enhance
Let's Enhance - український стартап, сервіс по обробці зображень, який за допомогою нейромереж збільшує здатність знімків, відновлює деталі і підвищує чіткість. Let's Enhance запустили в листопаді 2017 року і на сьогодні сервіс обробив більше мільйона фотографій.
В основі сервісу покладено кілька об'єднаних нейронних мереж. Щоб навчити нейронні мережі, надають сотні тисяч знімків парами в низькій і високій роздільності. Алгоритм нейронної мережі навчений на великій базі знімків, яка завдяки знанням типових об'єктів і текстур вміє відновлювати деталі і зберігати чіткі лінії і контури оброблюваних зображень. Let's Enhance може не лише збільшувати розмір фотографії в чотири рази, але й видаляти шуми і артефакти стиснення на знімках формату JPEG, домальовувати відсутні дрібні деталі, роблячи картинку максимально реалістичною (рис.7). Для ефективної обробки за часом і витратами, сервіс використовує потужності відеокарт - обробляти дані на CPU невигідно.
Рис.7. Результат виконання сервісу Let's Enhance
Для пересічних користувачів встановлено обмеження в 15 мегапікселів і 15 мегабайт для кожного завантаження. Користувачі з платною підпискою на послуги сервісу мають максимальний пріоритет в обробці зображень і можливість завантажувати картинки з роздільною здатністю до 30 мегапікселів.
Анімація фотографій Deep Nostalgia
Сервіс MyHeritage розробив функцію «Deep Nostalgia» для «оживлення» людей на фотографії. Нейромережа здатна зробити анімацію як з сучасних цифрових так й зі старих чорно-білих знімків. Щоб оживити портрет, потрібно зареєструватися на сайті та завантажити фотографію. Алгоритм обробки робить статичний знімок, і у людини на зображенні з'являється миміка - вона почне повертати голову, моргати і посміхатися.
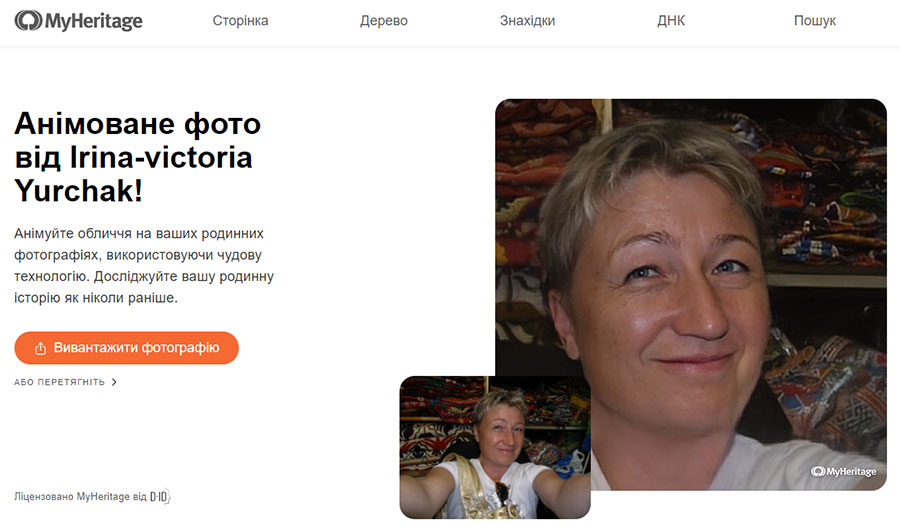
Рис.7. Результат виконання сервісу Deep Nostalgia
Накладання художніх фільтрів Dreamscope
Сервіс Dreamscope від компанії Lambda Labs дозволяє застосовувати до зображень до 19-ти різних фільтрів, перетворюючи будь-яку фотографію в психоделічну картину.
Програма заснована на розробках інженерів Google, які експериментували з новими системами розпізнавання зображень. Технологія Deep Dream підсилює на фотографіях ті елементи, які нагадують їй знайомі об'єкти. Наприклад, якщо програма навчена розпізнавати обличчя, то на всіх зображеннях, будь то зоряне небо або будівля, вони бачитиме фрагменти людських обличь і відтворювати їх на фотографії (рис.8).
Інженери виклали свою розробку у відкритий доступ в вигляді коду, що дозволило будь-якому користувачеві, знайомому з програмуванням, використовувати систему для реалізації своїх ідей. Додаток Dreamscope є доступним для простих користувачів, тому експериментувати з програмою можна до нескінченності, застосовуючи фільтри до зображень багато разів.
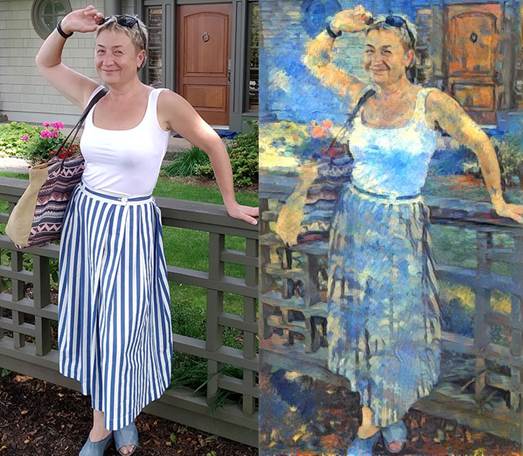
Рис.8. Результат виконання сервісу Dreamscope
Перетворення фотографії на картину Deepart
Німецькі вчені розробили алгоритм, який з великою точністю імітує будь-який графічний стиль і створює оригінальні картини на основі користувацьких зображень. Сервіс базується на технології нейронних мереж, що традиційно використовують для роботи з графікою (рис.9). Сервіс працює не лише з картинами, а й з архітектурною графікою.
Щоб створити стилізоване зображення, потрібно завантажити фотографію і вибрати стиль. Готовий результат сервіс надсилає на електронну пошту, оскільки обробка займає кілька хвилин і на сервісі довга черга. Середній час відповіді - близько 10 хвилин.
Для тих, хто не бажає чекати, розробники сервісу пропонують кілька варіантів платних підписок, що дозволяють не тільки звести до мінімуму час рендерингу шедеврів цифрового мистецтва, а й забирання обмеження на розмір вихідних зображень.

Рис.9. Результат виконання сервісу Deepart
Видалення фону Remove.bg
Безкоштовний сервіс, що дозволяє видалити фон на фотографіях без використання графічних редакторів. Після завантаження зображення система автоматично, з використанням алгоритмів штучного інтелекту виділяє об'єкти на передньому плані і прибирає все зайве. Наразі алгоритми краще справляються з видаленням фону з фотографій, на яких зображені люди (рис.11). Однак інструмент може працювати і іншими об'єктами на передньому плані, якщо вони чітко визначені. Також застосовують додаткові алгоритми, що покращують якість дрібних деталей.
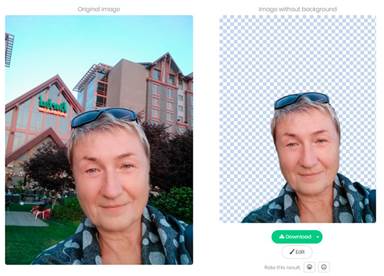
Рис.11. Результат виконання сервісу Remove.bg
До завантаження приймаються картинки будь-якого розміру, підсумковий варіант зображення (файл формату PNG з прозорим фоном) обмежений розміром 500 на 500 пікселів.
Редактор фотографій Nvidia AI Playground
Компанія Nvidia запустила платформу AI Playground для редагування фотографій за допомогою нейронних мереж. Інтерфейс платформи AI Playground дуже простий і експериментувати з обробкою фото можуть усі бажаючі.
Image Inpainting
Інструмент Image Inpainting використовує згорткові нейронні мережі, щоб видаляти одні деталі на фотографії і заповнювати їх більш придатними. Нові деталі добре поєднуються із зображенням і не вимагають подальшої обробки (рис.12).

Рис.12. Результат виконання сервісу Nvidia Image Inpainting
Image inpainting заповнює прогалини в зображенні, які користувач відмічає пензлем. Модель для реконструкції зображень надійно працює на нерегулярних прогалинах і створює семантично значущі передбачення, які поєднуються з іншою частиною зображення без необхідності додаткових операцій пост-обробки або змішування. Модель використовується з багатьма програмами, такими як, при редагуванні зображень для видалення небажаних деталей в зображенні, заповнюючи прийнятним контентом.
Компанія розробляє інші проекти, які базуються на нейронних мережах і глибокому навчанні.
Підбір музичного супроводу до зображення Imaginary Soundscape
Японська студія Qosmo розробила нейромережу Imaginary Soundscape, яка підбирає озвучення до завантажених фотографій чи зображень. Наприклад, до фотографії дитини в ліжечку нейромережа підбере дитячий плач, до зображення станції метро - звук потягу, до знімку пляжу - шум хвиль.
Люди при погляді на фотографію можуть уявити звуки, що в реальності супроводжують зображення: пейзаж пляжу може нагадати про звук гуркоту хвиль, жвава вулиця - звуки автомобілів і вуличної реклами. «Imaginary Soundscape» (Уявний звук) - це мережна звукова інсталяція, що сфокусована на цьому несвідомому досвіді. Користувач може пересуватися по Google Street View і занурюватися в уявні звукові ландшафти, що створені за допомогою моделей глибокого навчання.
Ця робота заснована на розробці крос-модальної методики пошуку інформації, такої як зображення-аудіо, текст-зображення, з використанням глибокого навчання. При наявності відео входів система була навчена двом моделям: одна добре налагоджена, попередньо навчена модель розпізнавання зображень обробляє кадри, а інша згорткова нейронна мережа зчитує звук як зображення спектрограми, еволюціонуючи таким чином, що розподіл вихідного сигналу стає якомога ближче до першого.

Рис.13. Результат виконання сервісу Imaginary Soundscape
Після навчання дві мережі дозволяють отримувати найбільш доречний звуковий файл для сцени з великого набору звукових даних про навколишнє середовище.
Звукові ландшафти, які генеруються штучним інтелектом, зазвичай виправдовують очікування, але іноді ігнорують культурний і географічний контекст (наприклад, шум хвиль на крижаному полі Гренландії). Ці відмінності і помилки змушують розробників задуматися над тим, як працює уява і наскільки плідне навколишнє звукове середовище.